Google Researchは18日(現地時間)、英語を対象にした機械学習用データセットを公開したことを、公式ブログで発表した。「MASC(The Manually Annotated Sub-Corpus)」「SemCor」を利用し、語意の注釈を加えるデータセットをGitHub上で公開している。
例えばNOAD(新オックスフォード米語辞典)は"ストック"を、「株式の発行および株式購読によって企業または法人によって調達された資本」と定義付けされているが、同時に「店内の品物」など他の単語が10以上も並んでいる。コンピューターが文章内に並ぶ特定の単語から、さまざまな意味を理解することが重要だとしながらも、多様な語意がAI(人工知能)を推進させるための課題として広く知られていた。この課題を解決するためGoogle Researchは語意のマッピングを行うことで、機械学習の精度を高めると同時に"語義の曖昧性"を解消できるという。
 |
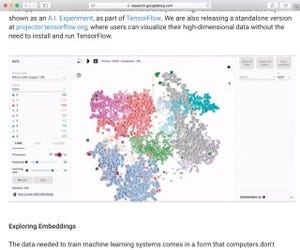
注釈ツールを利用して、評価作業を行う |
Google Researchは本データセットを利用し、文章内の意味をつなぎ合わせることでデータベースの自動構築が容易になると説明する。例えば「date palm」「date night」「web spam」「spam recipe」と似通った単語ながらも、まったく意味が異なる語義の曖昧性をなくし、正確なクエリーを返すという。その結果、名詞3万8,000ワード(SemCor)/5万ワード(MASC)など、合計で14万8,000ワードの注釈カウントにつながった。同研究所は英語の概念辞書(意味辞書)であるWordNetのマッピングを推し進めることで、自動的文書解析やAIアプリケーションの実現を支援する。
阿久津良和(Cactus)