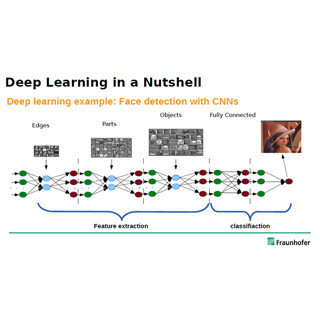
ISC 2016において、独German Research Center for Artificial Intelligence(DFKI)のDamian Borth氏が、Deep Learning(ディープラーニング)を使って、写真から形容詞と名詞のペアのクラス分けを行うという発表を行った。

|
|
ISC 2016で発表を行うDFKIのDamian Borth氏 |
Borth氏は、写真に写っているものの名前を識別するだけでは十分ではなく、それに付けられている形容詞が重要であるということで、形容詞と名詞のペアを認識するという研究を行っている。学習のためのデータとしては、YahooとFlickrが構築した100M(1億)のイメージとビデオを集めた「YFCC100m(Yahoo Flickr Creative Commons 100 Million)」というデータセットを使っている。

|
|
Creative CommonsでライセンスされているYahooとFlickrの作ったYFCC100mというデータセットを学習に使用した (この記事の図は、すべてISC 2016でのDamian Borth氏の発表スライドのコピーである) |
100Mの中でタイトルが付いていないのは3%、付いてはいるが「IMG_012345」とか「DSC_12061999」といった意味のないタイトルのものが26%で、意味のあるタイトルが付いているものが70%ある。しかし、意味のあるタイトルが付いているものも、平均するとその長さは3.08語であり、大部分は、あまり詳しいものではない。そして、説明文が付いているものは31.7%で、大部分のイメージやビデオには説明がない。

|
|
YDCC100mデータセットのタイトル,説明文、タグの付加状況 |
写真に写っているのが何であるかの認識だけでは不十分で形容詞が必要と言うのは、次の図を見れば良く分かる。2枚はドッグフードの宣伝であるが、左の写真には牙をむきだした恐ろし気な犬、右の写真には愛らしい犬が写っている。どちらが広告の効果が大きいかは明らかである。

|
|
犬の写真の下にドッグフードの広告を入れている。しかし、右と左では効果がまったく違っている |
次の写真も同様で、路上の車の写真の下に新車の広告を配置しているのであるが、左は炎上する車の写真で、購買意欲をそそるとは思われない。右はオープンカーで湖のほとりを快適に走っている写真で、購買意欲を刺激する。

|
|
爆発している車の写真と快適に走っている素晴らしい車の写真を、新車の広告に付けた例 |
このようなケースを適切に処理するために、ディープラーニングを使って、イメージの内容を理解して惹き起こされる感情を予測する。FlickrやYoutubeの写真では強い感情を反映しているものが多いので、コンセプトと強い感情を対応付けて、感情の検出を行うSentiBankを開発している。

|
|
ディープラーニングを使って、イメージの内容を理解して惹き起こされる感情を予測する |
感情であるが、次の図に分類されているように色々なものがある。例えば、強い喜びを表す「Ecstasy」、一般的な喜びの「Joy」、静かな喜びの「Serenity」があり、その右隣は尊敬、信頼、受け入れという3レベルの信頼感情が書かれている。

|
|
Plutchikの感情の輪 |
そして、Youtubeからは11万6000本のビデオ、Frickrからは15万枚の写真を使って24感情に対する形容詞、名詞ペアを抽出した。その結果、約3000の形容詞、名詞ペア(Adjective Noun Pair:ANP)が見つかった。使われている形容詞は約260種で、使用頻度の高いポジティブな形容詞は、「beautiful」、「amazing」、「cute」、使用頻度の高いネガティブな形容詞は、「sad」、「angry」、「dark」であった。使われている名詞は約1100個で、「people」、「places」、「animals」、「objects」、「weather」に関するものが多い。

|
|
Youtubeのビデオ166K本、Firckrの写真1万5000枚から24感情に対する形容詞、名詞ペア(ANP)を抽出した |
ANPの一例をあげると、次の図のようなものがある。雲に関しては、左は美しい雲、右は黒い雲である。左は可愛い犬、右は恐ろしい犬である。

|
|
上側の左は美しい雲、右は黒い雲である。下側の左は可愛い犬、右は恐ろしい犬のANP |