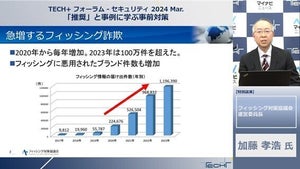
日々パソコンを利用していると、知らず知らずの間に、同じファイルをいくつも作ってしまいがちだ。ファイル名が違うだけで、内容が同じファイルが複数存在するなら、ディスクスペースの無駄であるだけでなく、ファイルを探すのに時間がかかり、作業効率が落ちてしまうことだろう。そこで、今回は、Pythonを利用して、高速に重複ファイルを削除するツールを作ってみよう。
重複ファイルの見つけ方
重複ファイルをどのように見つけたら良いだろうか。当然だが、二つのファイルを読み込んでみて、その内容が同じかどうかを比較するなら、そのファイルが重複しているかどうかを見分けることができる。
例えば、100個のファイルがあるなら、その100個のファイルの一つずつについて、他の99個のファイルと比較して内容が同じかどうかを調べるなら、重複ファイルを見つけることができる。これは、非常に愚直なやり方だが、仕組みが単純なので、まずは、この方法でプログラムを作ってみよう。
-
ファイルを一つずつ比較していく

ここで、プログラムを作成するのに際して、わざと複数の重複ファイルを作成し、checkというディレクトリにコピーしておこう。そして、Jupyter Notebookの起動パスにコピーしよう。
-
Jupyter Notebookで適当にファイルを用意しよう

その後、Jupyter Notebookを起動して、以下のプログラムを入力してみよう。もちろん、テストファイルを準備しなくても、プログラムの(*1)の部分を適当なパスに変えて試すこともできるだろう。
import os, glob
# 重複ファイルがあるかどうかを調べるディレクトリ --- (*1)
target_dir = './check'
# ファイルの一覧を得る --- (*2)
files = glob.glob(target_dir + "/*")
# 繰り返し重複があるか調べる --- (*3)
for f1 in files:
with open(f1, "rb") as f1p:
f1body = f1p.read() # 内容 --- (*4)
# 繰り返し調べる --- (*5)
for f2 in files:
# 同一ファイルなら比較しない --- (*6)
if f1 == f2: continue
# ファイルの内容を比較 --- (*7)
with open(f2, "rb") as f2p:
f2body = f2p.read()
if f1body == f2body:
print(f1, "==", f2)
print("ok")
プログラムを実行し、重複ファイルがあると、以下のように、同一内容のファイルの一覧を表示する。
-
重複ファイルを見つけたところ

プログラムを確認してみよう。(*1)の部分では、重複ファイルがあるかどうかを調べるディレクトリを指定する。(*2)では、glob.glob()関数を利用して、指定ディレクトリのファイル一覧を取得する。
(*3)の部分では、ファイルの一覧について、一つずつ重複ファイルがあるかどうかを調べていく。(*4)では、ファイルを開いてf1bodyに内容を読み込む。
そして、(*5)以降の部分では、比較対象のファイル一覧を一つずつを反復する。つまり、(*3)のfor文の対象ファイルf1と、(*5)のfor文の対象ファイルf2で、同一ファイルかどうかを調べる。(*6)では、全く同じファイルを反復しないように考慮し、(*7)の部分では、ファイルの内容を比較して、同一かどうかを調べる。もし、同一であれば、その旨をprint()で出力する。
高速に重複ファイルを検索しよう
ディレクトリ内のファイルが少ない時は、上記のような愚直なやり方でも、全く問題ないだろう。しかし、ファイル数が多いときには、非常に処理に時間がかかってしまう。というのも、例えば、100個のファイルについて比較するなら、外側のfor文で100回、内側のfor文で100回、100×100で合計1万回もfor文を回すことになるからだ。
そこで、for文を重ねないようにする方法を考えてみよう。これは、ハッシュ値と辞書型のデータを使うやり方だ。ファイルの一覧を得て、一つずつファイルを捜査するのは同じだが、ファイルを開いたときに、その内容の要約であるハッシュ値を計算し、それを辞書型の変数に覚えておく。そうして、過去に同じハッシュ値を持つファイルがあれば、それは、重複ファイルということになる。
ちなみに、ハッシュ値(あるいはダイジェスト値)というのは、データの受け渡しや保管の際に、そのデータが改変されていないか確認するために使われるものだ。あるデータが与えられた場合にそのデータを要約した値をハッシュ値と呼ぶ。データが異なればハッシュ値も異なるように工夫されている。
-
ハッシュ値と辞書型を使って重複ファイルを調べる方法

このやり方であれば、ハッシュ値を記憶するため、メモリはそれなりに消費するものの、for文を重ねる必要がないため、高速に重複ファイルを調べることができる。
それでは、実際のプログラムを見てみよう。
import os, glob, hashlib
# 重複ファイルがあるかどうかを調べるディレクトリ
target_dir = './check'
body_dict = {}
# ファイルの内容を返す関数 --- (*1)
def get_body(fname):
with open(fname, "rb") as f:
return f.read()
# ファイルの一覧を得て重複があるか調べる --- (*2)
files = glob.glob(target_dir + "/*")
for f in files:
# ファイルを開いてハッシュ値を調べる --- (*3)
body = get_body(f)
v = hashlib.sha256(body).hexdigest()
if v in body_dict: # 重複しているか --- (*4)
f2 = body_dict[v]
# 念のため実際に合致しているか調べる --- (*5)
if body == get_body(f2):
print(f, "==", f2)
# 実際に削除するなら以下のコメントを外す ---- (*5a)
# os.remove(f)
else:
body_dict[v] = f # --- (*6)
print("ok")
プログラムの実行結果はほとんど同じなので、プログラムの内容を確認していこう。プログラムの(*1)の部分では、ファイルの内容を読み込んで内容を返すget_body()関数を定義する。(*2)の部分では、ファイル一覧を得て一つずつ調べていく。(*3)では、ファイルを開いてハッシュ値を調べる。ハッシュ値を調べるには、hashlib.sha256()関数を使う。この関数は、SHA-256というアルゴリズムを用いてハッシュ値を計算するものだ。(*4)の部分では、過去に同じハッシュ値を持つファイルがあったかどうかを調べている。なお、一致するファイルがなければ、(*6)の部分で、辞書型の変数body_dictに今回のハッシュ値とファイル名を記憶する。
そして、プログラムの(*5)の部分では、厳密にファイルの内容が一致しているかどうかを調べている。というのは、非常に希だが、異なるデータでも、同じハッシュ値を持つことがあるので、ファイル全体を比較して、本当に合致しているかを確かめている。
最後に、プログラムを実行してみて、問題なさそうであれば、(*5a)の下にあるコメント文を解除して実行して見よう。すると、重複ファイルが実際に削除される。
まとめ
以上、今回は、Pythonを用いて、重複ファイルを削除するプログラムを二つ作ってみた。前者のプログラムは、実行に時間がかかるものの、メモリはそれほど消費しないタイプで、後者は、多少メモリは消費するものの高速に処理が完了するタイプだ。プログラムをどのように作るかによって、プログラムの速度やメモリ使用量が変わってくる。実際にプログラムを実行して、その動きを確認するなら、理解が深まるので、試してみよう。
自由型プログラマー。くじらはんどにて、プログラミングの楽しさを伝える活動をしている。代表作に、日本語プログラミング言語「なでしこ」 、テキスト音楽「サクラ」など。2001年オンラインソフト大賞入賞、2004年度未踏ユース スーパークリエータ認定、2010年 OSS貢献者章受賞。技術書も多く執筆している。