動作周波数やキャッシュ、分岐予測などの改善が図られたSPARC64 X+
今回のHot Chips 25では、富士通のSPARC64 X+とOracleのSPARC M6という2つの大型SPARCサーバプロセサと、IBMからはPOWER 8とzEC12メインフレームという全部で4種の大型サーバプロセサが発表された。今回は、その中のSPARC64 X+の発表を紹介する。
|
|
|
SPARC64 X+について発表する富士通の吉田利雄氏 |
富士通は昨年のHot Chips 24で16コアのSPARC64 Xプロセサを発表しており、今回の発表はそれに続くものである。名前が示すように、SPARC64 X+はSPARC64 Xのマイナーチェンジであるが、クロックを3.0GHzから3.5+GHzに引き上げ、L1キャッシュの改善や分岐予測の改善などの各種の性能向上を行っている。
SPARC64 X+は、SPARC64 Xと同じ16コア+24MBの共通L2キャッシュを持つプロセサである。また、製造プロセスも同じで、TSMCの28nmプロセスで作られている。しかし、同じ28nmプロセスでも、クロックはSPARC64 Xの3.0GHzから3.5+GHzに向上している。製品として3.5GHzになるのか3.6GHzあるいはそれより上のものが出来るのかは、まだ、明らかではないが、仮に3.5GHzとしても17%のクロックの向上であり、かなり、チューニングを頑張った結果であると思われる。
クロックが上がった結果、チップ全体での倍精度浮動小数点演算のピーク性能は382GFlopsから448+GFlopsに向上している。

|
|
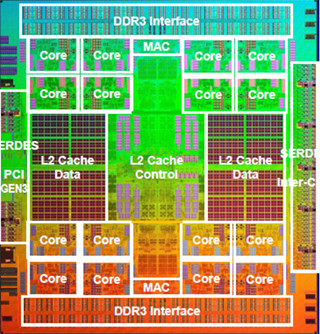
SPARC64 X+チップの概要 |
また、 SPARC64 Xチップが23.5mm×25mmであったのに対して、24mm×25mmと0.5mm幅が広がっている。また、トランジスタ数も2.95Bから2.99Bと40Mトランジスタほど増加しており、この部分が性能向上のために使われている。
メモリシステムは、SPARC64 Xと同じく4つのメモリコントローラを内蔵し、全体で8チャネルのDDR3-1600をサポートしていると考えられ、ピークバンド幅は102GB/sとなっている。なお、昨年のSPARC64 Xの発表ではSTREAM(Triad)の実測は65.5GB/sであり、実効的なメモリバンド幅はピークの2/3程度と思われる。
次の図は、SPARC64 X+のパイプライン構成図で、赤丸で囲んだ部分がSPARC64 Xから変更が加えられた部分である。

|
|
SPARC64 X+のパイプライン構成とX+での改良点を赤丸で示す図 |
まず、図の左端の分岐予測関係が強化されており、Pattern History Tableが16Kエントリから32Kエントリに増えており、Local Pattern Tableという構造が追加されている。マイクロアーキテクチャの改善を説明するスライドに、分岐先アドレスの変わる間接分岐に対応できるようになったという記述があり、名前から見て、ローカルパターンテーブルは、1つの間接分岐命令の分岐先の履歴を記憶して、どの分岐先アドレスかを予測するものではないかと思われる。
命令のDecode & Issue部分の改善は、レジスタウインドウをまたがるOut-of-Order実行を可能にするという改善である。

|
|
レジスタウインドウをまたがるOut-of-Order実行を可能にする改善と、分岐予測の改善 |
SPARCアーキテクチャはレジスタウインドウという特徴的な機構をもっている。SPARCでは32個の汎用レジスタは、8個のGlobalと8個のIn、8個のLocal、8個のOutという区別があり、関数をCallすると、呼び出し元の8個のOutレジスタは呼びだされた関数では8個のInレジスタとなり、8個のLocalと8個のOutには新しいレジスタが割り当てられる。また、Globalレジスタは呼び出し元と同じレジスタが使われる。
他のプロセサでは、すべてのレジスタが、呼び出し元と同じレジスタを共用するので、保存する必要があるレジスタの退避が必要になるが、レジスタウインドウでは、16個の新しいレジスタが使えるので、これで間に合えば、この退避とReturn時の復元の必要がない。従って、それだけ関数のCall、Returnの時間を短縮して、性能を改善することができる。
しかし、レジスタウインドウが切り替わると、一時に見える32個のレジスタのリネーム状況が変わってしまうという問題があり、SPARC64 Xまでは、CallやReturn命令を超えてOut-of-Order実行を続けることが出来なかったという。これをSPARC64 X+では隣接レジスタウインドウを含めた合計48個のレジスタのリネームが扱えるように改良し、Call、ReturnをまたぐOut-of-Order実行を可能にして性能を向上している。
SPARC64 XのL1データキャッシュは1Read、1Read/Write構造であったが、SPARC64 X+では、Writeポートを独立させ、2Read、1Write構造としている。従来は2つのReadか1つのReadと1つのWriteしか同時には実行出来なかったが、これにより、2つのReadと、それとは独立の1つのWriteが並行して実行できるようになった。
図の右下のグラフは、SPARC64 VII+を1.0とした相対性能で表されているが、独立Writeポートの追加により、SPARC64 XからX+で、L1データキャッシュのスループットは、Read Onlyの場合は2.5→2.85、Write Onlyの場合は2.1→3.45、Copyの場合は2.05→3.75に向上している。Read Onlyの場合の向上はクロックの向上分と見られるが、Write Onlyでは約64%、Copyでは約83%向上しており、クロック向上分を差し引いても50%かそれ以上のスループット向上が得られている。

|
|
L1データキャッシュは書き込みポートを独立させてスループットを改善 |
また、ロックなどの排他制御の実現に使用されるAtomicメモリアクセスの性能を改善し、プリフェッチのスループットも改善したという。しかし、具体的な数字がなく、どの程度の改善かは分からない。Intelなどの発表でも、Atomicの実行時間の改善はサイクル数を上げており、学会発表としては数字を書いてもらいたいところである。