Preferred Networksのディープラーニングシステム開発
|
|
|
ディープラーニングのビジネス応用の課題について講演するPreferred Networksの大野氏 |
Preferred Networksは、東京大学発のベンチャーの「Preferred Infrastructure」から2014年10月にスピンオフした会社で、IoTにフォーカスし、ディープラーニングなどの最新の技術を開発している。
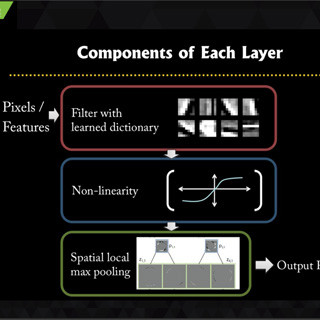
同社のディープラーニングについて、「ディープラーニング最近の進展とビジネス応用への課題」と題して同社の大野健太氏が講演を行った。
IoTで大量のセンサが発生する全部のデータをセンターに送ると膨大なデータ量になってしまう。また、監視カメラなどのすべてのデータをクラウドに上げるとプライバシーの問題も発生する。このため、Preferred Networksは、ローカルにデータ処理を行い、抽出された情報をクラウドに上げてグローバルな解析を行う「エッジヘビーコンピューティング」を提唱している。

|
|
IoTで大量のセンサデータが発生する場合、すべてのデータをセンターに集めることは問題が多く、エッジでローカルにデータ処理を行い、得られたデータをクラウドに上げて解析するエッジヘビーな処理が必要となる |
次の図は、同社のDeep Learningシステムを使って街頭の風景から人物を認識し、向き、性別、帽子の有無を認識する例である。

|
|
Deep Learningを使って街頭の風景から人物を認識し、向き、性別、帽子の有無を認識する例 |
このような情報を取得できると、通行人の男女比、年齢構成、ジャケットや帽子の着用割合、さらにはどのように移動しているかの追跡データが得られ、マーケティングや街づくりに利用できる。

|
|
このような解析で、通行人の男女比、年齢構成、ジャケットや帽子の着用割合、さらにはどのように移動しているかの追跡データが得られる |
また、Preferred Networksはディープラーニングを使った創薬の効率化にも取り組んでいる。

|
|
薬品候補物質の活性予測。PubChemのデータベースから、DNNを使ってそれぞれの物質の活性を予測する精度を向上 |
また、1個のGPUでは性能に限界があることから、複数GPUに学習を分散し、学習結果を共有することでスケーラビリティを確保する方法を検討している。また、正解として与えられた教師データだけでなく、訓練済のネットワークの分類結果も正解データとして使う蒸留(Distillation)などの手法を使ってノード間の通信データ量を削減しているという。

|

|
|
東工大のTSUBAMEを使って3ノードの連携を行うコミュニティラーニングを行った |
コミュニティラーニングのスケーラビリティ。4ノードまではスケール、8ノードでは6.9倍であるが、ほぼスケールしている |
ディープラーニング(深層学習)をビジネスに応用して行くには4つの課題があるという。その第1のポイントは、大量の学習データが必要であり、データを継続的に収集・管理する必要があることであるという。

|
|
ディープラーニングをビジネスに使うには大量データを継続的に収集・管理する仕組みが必要である |
第2のポイントは、技術の進歩のスピードが速く技術が枯れにくく、それに追いついていくことが必要なことである。一度、システムを作ればそれで良いという訳には行かない。

|
|
進歩が速く技術が枯れないので、それに追いついて行かなければならない |
第3のポイントは、技術だけではなく、環境も急速に変わり、それにつれてディープラーニングシステムの精度も低下していく。定期的に精度の測定を行い、自動的に新しいデータを加えて再学習するなどの精度劣化に対応できるシステム設計になっていることが必要である。

|
|
インターネットの世界は、新しいサービスの開始などでユーザ層が変わるなど、システムの外部環境が変化する。そうすると、以前の環境に合わせて学習したシステムの精度が低下してしまう。これを検出して自動的に補うシステム設計が必要 |
第4の課題は、ディープラーニングのシステムは自動的に学習してしまうので、予期したように動かない場合に、何が悪く、どうすれば直せるのかが分かりにくいという点があり、これに対処するデバッグ手段が必要であるという。

|
|
ディープラーニングシステムの予測精度が悪いことは、最後のテスト時や運用を開始してから分かる。しかし、何が悪くて、どうすれば直せるかが分かりにくい |
Preferred Networksで開発している薬剤候補の化合物の活性を予測する創薬向けのディープラーニングシステムなどでは、1個のGPUでは学習スピードが不足であり並列化が必要である。これに対して、「コミュニティラーニング」と呼ぶ、並列分散システムで8ノードまで性能がスケールし、精度が向上することを示した。今後の課題は、さらに性能を上げるための、ノード数の大規模化やヘテロジニアス化であるという。
ビジネス応用にあたっては、大量データの管理、技術の枯れてなさ、予測精度劣化への対応、原因の切り分けなどのさまざまな課題があることを指摘した。

|
|
コミュニティラーニングで8ノードまで性能がスケールし、化合物活性予測の精度が向上した。今後の課題はノード数の大規模化やヘテロジニアス化。また、ビジネス応用にはさまざまな課題が存在する |
一般的には、ディープラーニングシステムを開発するためには、Caffe(カリフォルニア大学バークレイ校)、Theano(モントリオール大)、Torch(GoogleやFacebookなどのエンジニアのコミュニティ)と言ったフレームワークが使われることが多いが、Preferred Networksでは独自の「Chainer」と呼ぶフレームワークを開発している。
Chainerは時系列データを分析するRNN(Recurrent Neural Network)やLSTM(Long Short-Term Memory、RNNの一種)の開発に強い、ネットワークの動的構築ができるという特徴があるという。そして、現在、最高の認識率を持つGoogLeNetのアーキテクチャをCaffeで記述すると2058行を要するが、Chainerを使えば167行で記述できるという。