MathWorksフェローのJim Tung氏 |
MathWorksは10月31日、同社のフェローであるJim Tung氏を招き、2017年9月21日に発表したMATLAB/Simulinkの最新リリース「Release 2017b」の報道陣向け説明会を実施した。
既報の通り、最新リリースでは、エンジニアや研究者が比較的容易にディープラーニングを扱えるように機能が追加されたほか、「Text Analytics Toolbox」などの新製品の追加、更新およびバグ修正などが行われている。 説明会では同リリースの一番の特徴である、ディープラーニングに焦点があてられた。Jim Tung氏は「今回のリリースでは、ディープラーニングになじみがない人にも使える機能が追加されている」とし、新機能の説明を行った。
なぜ今、ディープラーニングが必要なのか
ディープラーニングとは、画像や文章、音声などのデータから直接学習する、機械学習手法の1つ。2012年から研究が活発に行われるようになり、2015年には、人間よりも高い認識精度をもつようになった。

|
画像データを読み込ませ、誤認識した比率を調査。点線が人間の認識能力を示している。初期のマシンラーニングでの認識能力は人間よりも劣っていたが、ディープラーニングの登場によって、その性能は大幅に上昇した |
また、認識のスピードも高く、ネットワーク上には大量のデータがあることやGPUによる高速演算が可能になることから、同技術の研究開発は日々勢いを増している。
ラベリング機能で高効率化
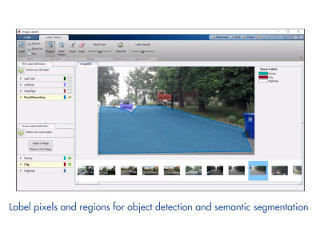
従来、MATLAB上でモデル学習を行う際には、機械に認識させたいオブジェクトがある場合、1コマずつ人間がオブジェクトを選択する必要があった。しかし、最新のリリースでは、最初の1コマを選択するだけで、残りのコマは機械が勝手に追跡して選択できるようになった。例えば、車が道路を走っている100枚の画像があるとき、1枚の画像で道路を選択し、「走行可能」と設定することによって、残りの99枚の画像でも同様の処理が行われる。

|
画像の道路部分を選択し、「走行可能」と設定するだけで、他の画像でも同様の設定がなされる |
「GPU Coder」で「TensorFlow」の7倍のパフォーマンスを実現
また、ディープラーニング用のフレームワークである「Caffe」やGoogleの「TensorFlow」などで公開されている学習済みモデル(Pre-trained Model)を取り込むことが可能となった。これにより、ユーザーは、転移学習によって、MATLAB上で自身の目的に応じたモデルを作成することができるようになる。

|
「Caffe」やGoogleの「TensorFlow」などで公開されている学習済みモデル(Pre-trained Model)の取り込むことが可能になった |
さらに、ディープラーニングの演算速度の高速化も実現。MathWorksは、並列コンピューティング技術のナレッジがあり、ユーザーのコンピューティングの高速化をサポートする。ユーザーがGPUをいくつ使用していても、それがローカル環境であれ、AWS上であれ、GPUのネイティブ言語でなく、MATLABからの操作が可能になる。
また、AlexNetを用いたベンチマークにおいて、MATLABの実行速度はTensorFlowの約2.5倍を示している。すでにこの時点でMATLABの有用性はあるようだが、Jim氏は「これで満足する気はなかった」といい、今回のリリースより、新機能の「GPU Coder」を追加。これは、ディープラーニングモデルをNVIDIA用CUDAコードに自動変換するもの。これにより、ディープラーニングインタフェース用に生成されるコードのパフォーマンスは、配布モデルにおいてTensorFlowの約7倍を実現するとしている。

|

|
AlexNetを用いたベンチマークで、MATLABの実行速度はTensorFlowの約2.5倍を示している |
GPU Coderの実行速度は、TensorFlowの約7倍を示す |

|
ディープラーニングモデルをNVIDIA用CUDAコードに自動変換する「GPU Coder」 |
なお、ディープラーニング機能の詳細については、「MATLAB Onramp」Webサイト(英語)から確認できる。