|
|
|
京都大学大学院医学研究科の奥野恭史 教授 |
ヴァイナスは10月13日、プライベートカンファレンス「VINAS Users Conference 2016」を開催。基調講演として、京都大学大学院医学研究科の奥野恭史 教授が「スーパーコンピュータが拓く創薬計算の未来」と題し、日本のスーパーコンピュータ(スパコン)「京」を用いた創薬向けシミュレーションの解説などを行った。
医薬品の開発には、10年以上の期間と1000億円以上の研究開発費が必要と言われており、研究開発における費用対効果が求められるようになってきた。そこでHPCやITを活用することで、効率的な開発につなげることができないか、というニーズが増しつつある。
そこで奥野教授は、京を活用した創薬研究プロジェクト「新薬開発を加速する「京」インシリコ創薬基盤の構築」を主導し、そうしたニーズに応える取り組みを進めてきた。同氏は「京の始動とともに多くの製薬企業と連携して、医薬品開発におけるスパコンの活用を推進してきたが、この分野はそうした取り組みが遅れており、京を使う、といったときも、製薬企業からは、本当に使えるのか、といった疑問があがってきた」と当時を振り返る。

|
|
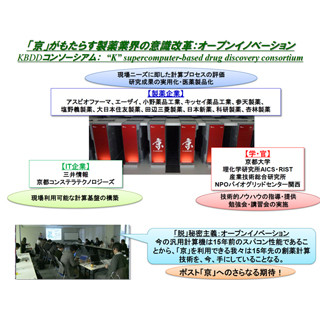
新薬開発を加速する「京」インシリコ創薬基盤の構築プロジェクトに参加する企業などの概要 (以下のスライドは、すべて「VINAS Users Conference 2016」における奥野教授の発表資料より抜粋) |
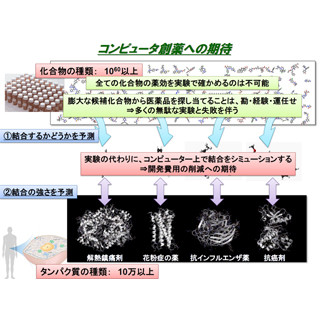
その成果の概要については、すでに過去にHisa Ando氏が2回にわたって掲載(前編、後編)しているので、詳細は割愛するが、創薬の候補となる化合物の種類は1060以上あり、どの化合物がターゲットとするタンパク質と結合するのかを探索するだけでも、膨大な時間が必要となっていたほか、副作用を減らすために、ターゲットのタンパク質のみと強く結合してもらいたいというニーズがあるにも関わらず、従来は演算性能の限界から、タンパク質を固定して反応を見るという演算であったため、予測精度は5%程度にとどまっていた。
この2つの課題を京を使って解決しようというのがプロジェクトの取り組みだが、奥野教授は、「化合物とタンパク質の結合予測の超高速化」を「ビッグデータ創薬」、「精密な結合シミュレーションによる予測制度の劇的向上」を「シミュレーション創薬」と呼び、実用性の検討を進めてきた。

|
|
京を活用して2つの新たな創薬手法の確立を進めている |
その結果、ビッグデータ創薬として世界最大規模となる189.3億ペアの結合予測を達成した。これは16ノードの汎用計算機では約2年かかる計算だが、京の8万ノードを使うと5時間45分で終えることができたという。
また、当時は機械学習の一種であるSVM(サポートベクターマシン)などを用いて研究を行っていたが、近年のディープラーニングの急激な進化を踏まえた研究も実施。Intel Chinaと協力して行った実験では、GPUコンピューティングのコードをXeon向けにチューンしなおして、約25万件のタンパク質GPCRの相互作用データを処理したところ、SVMでは12時間で予測値91.4%かかったものが、25分で91.0%で終えることができたほか、400万件の場合でも220分で96.4%と、さらなる高速演算かつ高精度化を可能にしたとする。

|
|
ディープラーニングを用いてGPCRの25万/100万/200万/400万相互作用データを処理した結果 |
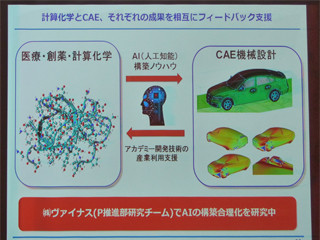
さらに、従来の手法では、化合物とタンパク質の構造を用意した後に、結合する可能性を計算していたが、これを人工知能(AI)を活用することで、ターゲットとなるタンパク質だけを提示し、最適な化合物をAIが考える「次世代型インシリコ創薬(De novo Design)」を考案。結果、AIが自ら考えて最適な化合物を導き出すことが可能になったという。

|
|
化合物の合成を自動的に世代を重ねるごとに高いスコアのもののみを残し進化させていくことで、最適化を図ることが可能となってきた |
一方のシミュレーション創薬は、アンサンブルシミュレーションによって、正確かつ頑強にタンパク質と化合物の結合の強さ(結合自由エネルギー)を求めるというものだが、結合の強さを正確かつ頑強に計算をするには、分子の動きや溶媒(水分子)も含めた長時間シミュレーションを実行する必要があり、従来の演算能力では非現実的であったが、京による大規模並列演算でこれを実現。「150個の化合物とタンパク質との結合の強さを計算するのに、通常の汎用機では20年かかるが、京をフルに利用すれば1週間程度で計算が可能」とのことで、HPCAE(High Performance Computer Aided Engineering)の有用性が示されたとする。

|

|
|
複数の結合状態を計算し、それを組み合わせることで、最終的な結果を得る。これがスパコンを活用するという点で重要であり、こうした手法はメジャーになってきているという |
|
ただし、「京を使って、どのような薬剤ができたのか、ということを良く聞かれるが、こうして候補が出来た後も、製薬企業が開発を継続し、治験を行い、承認を受け、といった手順を踏む必要があり、やはり長い時間がかかる」と、今すぐに、薬として成果を見せられる状況ではないことも強調。その一方で、京大として、個人のゲノムを調べることで、どういった薬剤が効きやすいのか、といった研究をがんセンターにて行っており、薬剤耐性をがんが獲得するメカニズムの解明なども含め、シミュレーションを活用して研究を進めているとした。
ちなみに奥野教授は2020年ころの稼動を目指しているポスト「京」での利用に向けた創薬向けオープンソースアプリケーションの開発プロジェクトも理化学研究所の立場から進めている。「京で実感したのは、京が始動したおよそ5年ほど前に、製薬企業が利用できるようにはじめて、3年程度の実証が必要だった。スパコンは3年立てば最先端ではなくなる。だからこそ、ポスト京ができたタイミングで、製薬企業の現場ですぐにポスト京を活用できる環境を構築する必要があり、産官学で協力して取り組んでいく必要がある」と強調。ヴァイナスとも、こうした話を踏まえて、医薬とITの結びつきを強め、実際に製薬企業が使えるように協力していきたいとした。

|

|
|
創薬関係はポスト「京」の重点課題に位置づけられている。また、プログラミングの知識や技術がなくてもスパコンで分子シミュレーションが利用できるためのソフトウェアやGUIの開発も進められており、ポスト「京」向けの計算手法も順次実装されていく予定だという |
|
最後に奥野教授は、「これまでは創薬をデザインするという分野での取り組みが中心であった。しかし、計算機医療の可能性は薬剤の評価なども含め、さまざまな分野で活用できると思っており、プロセスの最適化を考えていく必要がある」と指摘。「それぞれの医療分野の研究者が努力して薬剤が上市されることになるが、計算機がそれを助け、最適な方向性が示されるような世界を実現するためには、医療系に工学系に知識が入ってくることで実現できるようになるはず」との持論を展開。今後、ますますスパコンやAIと医薬の世界の結びつきが強くなっていくことへの期待を示した。

|
|
医学分野にスパコン・AI・ビッグデータ・シミュレーションといった工学系のアプローチが組み合わさることで、創薬や医療の進化が促されることが期待される |