GTC 2015の基調講演で、Jen-Hsun Huang CEOは次の4つ発表を行った。

|

|
|
Jen-Hsun Huang CEOは基調講演で、新GPU、非常に高速のBox、ハイエンドGPUのロードマップ、自動運転の4項目の発表を行った。全項目に"and Deep Learning"がついているのがミソである。 |
新GPUであるTitan Xを手にして基調講演を行うJen-Hsun Huang CEO |
Titan Xの発表については、すでにレポートしたので詳しくは触れないが、3072コアを集積するMaxwellアーキテクチャのGM200チップを使うトップエンドのコンシューマ向けGPUである。ハイエンドのGTX 980と比較するとCUDAコア数は1.5倍に増加し、コアクロックは多少低めに抑えられているが、ほぼコア数に比例して演算性能が向上している。
GM200チップの1つの目玉がFP16と呼ぶ16ビットの浮動小数点数のサポートである。全体が16bitしかないので、Exponentは5bit、Fractionは10bitであり、値の有効桁数が少なく、表現できる数の範囲も狭いが、画像などの表現には十分である。そして、通常GPUが扱う32ビットのFP32の半分のメモリで済み、演算器を多少改造すれば1サイクルに2つの数の演算を並列に実行できる。このため、演算性能が倍増するというメリットがある。
画像認識を行うDeep Learningでは、入力は画像データであり、FP16で十分である。そして、認識のアルゴリズムの主要な部分はGPUの得意な行列積計算である。つまり、数値としてFP16を使って行列計算を行うと、Titan Xは非常に高い性能を発揮する。

|
|
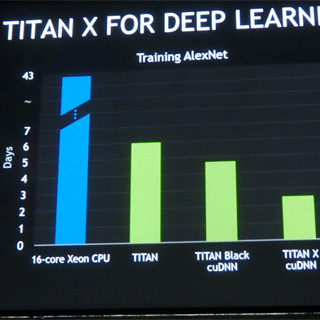
16コアXeonでは43日かかるDeep Learningの処理がTitan Xでは2.5日 |
この図に見られるように、Titan Xは16コアXeonと比べて約17倍の性能であり、Deep Learningに向いているというアピールである。この主張は正しいのであるが、やはり、Titan Xはゲーマーなどを中心とするコンシューマ向けの製品であり、市場規模からみてもDeep Learningはおまけである。従って、New GPU for Deep Learningではなく、New GPU and Deep Learningとなっているのは、至極もっともである。
Deep Learningのソフト開発を容易にする目的でCaffe、Torch、Theanoなどのライブラリが開発されている。これらのライブラリを使用すると一般的な処理手順はライブラリとして用意されているので、一般的なニューラルネットワークの動きや学習の手続きの記述を簡単に行うことができる。

|
|
Deep Learningのソフト開発では、CaffeやTorch、TheanoなどのDeep Learning用のライブラリを使って書かれるのが一般的である。NVIDIAのDIGITSはGPU最適化されたこれらのライブラリがインストールされていて、すぐに使い始めることができる |
NVIDIAのDIGITS DevBoxという製品には、これらにライブラリと、ディープラーニングを実行させる環境がインストールされている。これらのライブラリやDIGITSはオープンソースであるので、自分でダウンロードしてインストールすることもできるが、DevBoxとして買ってしまえば、インストールの手間が省ける。

|
|
ニューラルネットワークの構成を編集したりしてラーニングを実行させ、その進捗をモニタできる。また、各層の動きを視覚的に確認することもできる |
そして、DIGITS DevBoxのハードは、x86マザーボードに4基のTitan Xが搭載されたものとなっている。元々は自社用に開発されたものであるが、欲しい人からは注文を受け付け、15,000ドルで5月から発売する。

|
|
DIGITS DevBoxの外観は大型のデスクトップPCで、x86マザーボードと4基のTitan Xが入っている |
そして、GPUのロードマップとしては次の図が示された。昨年のロードマップと比較すると2018年にVoltaが追加されている。この図の縦軸はSGEMM(単精度行列乗算)/Wで、2016年のPascalはMaxwellの2倍、2018年のVoltaはPascalの2倍弱という感じである。

|
|
昨年と比べると2018年にVoltaが追加された。SGEMM/W性能ではPascalはMaxwellの2倍、Voltaは2倍弱という感じである |
これに加えて今回はFP16を使う半精度行列乗算の性能/Wの図が発表された。この2枚の図を比べると、Maxwellはどちらの図でも24位の性能であるが、Pascalは、単精度のSDEMMでは40位であるのに対して半精度のHGEMMでは80程度と2倍の性能になっている。

|
|
半精度行列乗算(HGEMM)で見た性能/Wの推移 |
半精度をサポートするTitan XはMaxwellアーキであるので、PascalからしかHGEMM性能が上がらないのはおかしいと思うのであるが、どうもNVIDIAは半精度の本格サポートはPascalからと区切りたいようである。
メモリバンド幅の観点では、 HBMをGPUと同一のパッケージに搭載する2.5D実装となるPascalでは750GB/sと、GDDR5を使うMaxwellと比べて3倍のメモリバンド幅が得られている。しかし、Voltaでは、900GB/sへの向上となっており、同一テクノロジでのクロック向上程度の改善となっている。

|
|
メモリバンド幅の点では3DスタックのHBMを同一パッケージに搭載するPascalでは、Maxwellの3倍のメモリバンド幅となるが、Voltaでの上積みは小さい |
HGEMMでは、PascalはMaxwellの4倍弱の性能向上。メモリバンド幅は絶対値では3倍であるが、データのサイズがFP16で半減しているので、結果として6倍のデータをメモリとの間で転送できる。Deep Learningの処理では、これらを合わせてGPU部分で5倍、そしてNVLINKでGPUチップ間の転送が速くなることから2倍の性能向上を見込んで、PascalはMaxwellの10倍の性能と称している。しかし、性能向上はプログラムによっても変わり、これは非常に粗い見積もりであるという。

|
|
FP16の使用で演算部分では4倍、メモリバンド幅3倍とデータサイズ半減でメモリネックの部分は6倍の性能向上。全体ではGPU部の性能は5倍と見積もっている。そしてNVLINKの採用で2倍と見込んで、全体的には、Deep Learningでは、PascalはMaxwellの10倍の性能と称している |
4つの発表の最後が自動運転である。現状のADAS(Advanced Driving Assistant System)は前の車や歩行者、交通標識、道路のレーンマーカーなどを専用のロジックで認識して運転を補助しているが、NVIDIAはディープニューラルネットワーク(DNN)が取り入れられていくと考えている。

|
|
Deep Learningの進歩から、近い将来、自動運転にはディープニューラルネットワーク(DNN)が取り入れられるとNVIDIAは考えている |
そして、従来のADASの画像処理に加えてDNNの処理も可能なプラットフォームとしてDrive PXと呼ぶ車載用のボードコンピュータを発売することを発表した。

|
|
従来のADAS画像処理に加えて、DNNの処理に対応できるプラットフォームとして右側に示すDrive PXボードを発売する |
Tegra X1を2個搭載したDrive PXは5月から10,000ドルで販売されるとのことである。なお、DNNの学習は多数の画像を使って、正しい識別ができるようにパラメータの調整を繰り返すので非常に時間が掛かるが、学習が終わってパラメータが決まると、1画面の理解は0.1秒以下でできるので、Tegra K1程度の能力があればよい。
なお、某記者が、999ドルのTitan Xを4台搭載したデスクトップPCであるDIGITS DevBoxが15,000ドルは高いと文句を言っていたが、それを言うならDrive PXの10,000ドルはバカ高い。この値段では数1000万円の超高級車にしか搭載できない。筆者は100ドルの間違いではないかと思っている。