(前編はコチラ)
(中編はコチラ)
5月7日追記:初出時、地球シミュレータは640ノードをクロスバで接続し共通メモリとなっていると記述しておりましたが、誤りであったことから、当該箇所を含め、本文を改訂させていただきました
NGVではシングルチップの分散メモリノードとなった
NECのベクトルスパコンの名作である地球シミュレータでは、1個のベクトル型計算プロセサ(AP)が1チップに集積されており、8台のAPが共有メモリをアクセスする構造になっていた。8台のAPの合計の演算性能は64GFlops、共有メモリのバンド幅は256GB/sである。これは4Byte/Flopという高メモリバンド幅であり、メモリアクセスがネックになって計算性能がでないということはほとんど発生せず高い実効性能が得られる。しかし、APと共有メモリを接続するクロスバや共有メモリが大規模になり、コストが高いという問題を持っている。
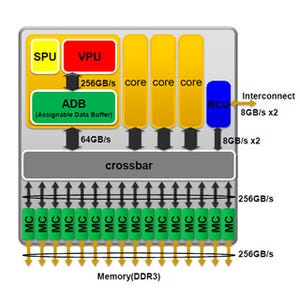
NGVでは、ほぼ16台のAPに相当するベクトル演算器を1コアとし、これを4個1チップに詰め込み、1個のLSIで256GFlopsの演算性能となっている。メモリバンド幅の点では、各コアのADBのメモリバンド幅は地球シミュレータの1ノードと同じ256GB/sであるが、コアあたりの共有メモリのバンド幅は64GB/sで地球シミュレータの1/4と割り切っている。
地球シミュレータの計算ノードはAPチップを中心とする計算プロセサ8台と32台のメインメモリからなり、これらの間を接続するクロスバやケーブルも膨大であり、1筐体に2ノードしか収容できなかったのであるが、NGVのプロセサチップは地球シミュレータの計算ノードの4倍の性能を持っているが、 NGVではADBや共通メモリアクセスのクロスバなどがチップ内に集積され、次の図に示すように、37cm×11cmのボード1枚に収まってしまう。プリント板の中央にCPUチップ、その左右に8枚ずつのDDR3 DIMMを搭載し、左側に8GB/sのシリアルインタフェースの2個のコネクタが並ぶというすっきりした構成になる。

|
|
NGVのノードカード。中央にCPU、左右に計16枚のDDR3 DIMMが搭載され、左端にFat Tree Swtichへの接続するコネクタが搭載されている (出典:Cool Chips 16におけるNECの百瀬氏の発表スライド) |
CPUの信号ピン数が多いので、パッケージやプリント板は、多少、高そうであるが、これまでのNECのスパコンのようなすごい部品は使っておらず、コストは大幅に下がっていると思われる。
なお、この写真ではCPUチップが見えるようになっているが、実際には、水冷のヒートシンクが取り付けられてチップは見えない。後に掲載するシステムの階層の写真の中のモジュールの写真を良く見ると、水冷のヒートシンクと給排水のパイプが見える。
NGVスパコンのシステム構成
最初の原稿で、地球シミュレータは640ノードをクロスバで接続し共通メモリとなっていると書いたが、これは筆者の間違いで、ノード間は別個のメモリ空間となる分散メモリとなっていた。そして、ノード間は1段のクロスバで接続し、短い遅延時間でメモリ間のブロック転送ができるようになっていた。
講演の中では明確に述べられなかったが、百瀬氏に質問したところ、NGVも基本的には同じアーキテクチャであり、シングルチップの中の4コア、64VPU間では共通メモリであるが、ノード間では分散メモリとなっている。NGVのプロセサチップからは2チャネルの8GB/sのポートが出ており、これらをFat Treeスイッチで接続してシステムを構成するという回答であった。ノード間接続が1段のクロスバではなく、Fat Treeとなったのは前世代のSX-9と同じである。

|
|
NGVシステムの構成の推測図。NGV CPU 1個からなるノードがFat Tree Switchを経由して接続されている |
後に述べるように1筐体には64ノードが収容されるので、128ポートのFat Tree Switchを使って筐体内のノードを接続し、上位のFat Tree Switchで筐体間をつなぐという上の図のような構成になっていると推測される。
そして、分散メモリで問題ないかと百瀬氏に聞いたところ、一部のユーザからは共通メモリが欲しいという要求があるものの、地球シミュレータもノード間は分散メモリであり、主要なユーザは、すでにMPIによるノード間通信を使っており、大きな問題にはならないという回答であった。
NGVのノードのピーク演算性能は256GB/sであるのに対して、Fat Tree Switchへの接続は出入りを合わせて32GB/sであり、計算ノードの演算性能とインタコネクトのByte/Flopは0.125B/Fになる。
京スパコンの計算ノードが128GFlopsの演算性能に対して、他ノードとの通信は40GB/sの通信バンド幅を持ち、おおよそ0.3B/Fであったのと比較すると、NGVのノード間通信のB/F比は半分弱である。NGVは、京スパコンと比較すると、ノード内では高いB/Fを持つが、ノード間接続のB/Fは低いというシステム設計となっている。
1チップと16DIMMからなるノードカードを最小単位として、次の図のような階層でNGVスパコンは作られている。

|
|
2枚のノードカードを並べたモジュール8枚をケージに収容し、4個のケージを1つの筐体に収容している。筐体あたり64ノードで、ピーク演算性能は16TFlops、メモリバンド幅は16TB/sとなる (出典:Cool Chips 16におけるNECの百瀬氏の発表スライド) |
2枚のノードカードを平置きにして並べたものがモジュールで、1つのケージに8枚のモジュールを収容する。そして、1筐体には4ケージを入れ、筐体全体では64ノード、16TFlopsというピーク演算性能となる。また、メモリバンド幅は16TB/sである。
地球シミュレータでは16TFlopsには128筐体、現状のSX-9は10筐体を必要としており、NGVは地球シミュレータの128倍、SX-9の10倍の密度となっている。しかし、この筐体が64本で1PFlops、10PFlopsには計算ノード640筐体と筐体間Fat Tree Switchの筐体が必要となり、800筐体あまりを使っている京スパコンと比べて、多少、高密度という程度で、あまりコンパクトとは言えない。なお、Cool Chipsでの発表では、名称は決まっていないとのことでNGVと呼んでいたが、この筐体の写真にはSX-Xと書かれている。
以上のようにCool Chips 16でNECの次世代ベクトルスパコンの構成が明らかにされ。1チップの計算ノードとなったことでノード内の共通メモリの実現が大幅に簡素化されており、百瀬氏によると、高いB/Fを必要とする用途ではPCクラスタに対して競合力のある価格になるとのことであった。