ドイツのハンブルグで開催されたISC(International Supercomputing Conference)に合わせて恒例のTop500リストが更新され、理化学研究所(理研)と富士通が開発中の「京」スパコンが8.162PFlosで1位に輝いた。「1位じゃないとダメなんですか」発言もあったが、とにかく1位になったことは日本としては2002年から2004年に1位を占めた地球シミュレータ以来、久しぶりの快挙である。また、富士通としては1993年から1995年に1位を占めたNWT(Numerical Wind Tunnel:航空宇宙技術研究所の数値風洞)以来の1位である。

|

|
|
Top500 1位の賞状(出所:理研次世代スーパーコンピュータ開発実施本部のWebサイト) |
表彰を受けた富士通の佐相副社長(左)と理研の渡辺プロジェクトリーダー(中央)。右端は主催者のMeuer教授(出所:理研次世代スーパーコンピュータ開発実施本部のWebサイト) |
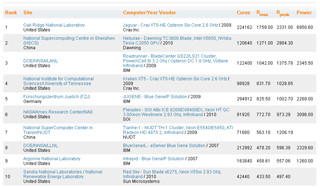
しかし、工程から見て、フルシステムのLINPACKを測定してTop500に登録するのは、早くても2011年11月と思っていた筆者にとってはこの発表は驚きであった。今回のシステムは548,352コアのシステムで理論ピーク性能は8.77363PFlopsである。そして、今回のLINPACK性能の測定は10,725、120元の連立1次方程式を解いて8.162PFlopsを実測しており、1000万元を超えた測定はTop500の歴史でも初めてである。
「京」システムはLINPACK 10PFlopsが目標であり、理論ピーク性能は公表されていないが、おおよそ、11PFlops程度の規模と推測される。つまり、今回1位となったシステムはフルシステムの80%程度の計算ノードでの測定ということになる

|
|
2011年6月の「京」コンピュータの設置状況(出所:理研次世代スーパーコンピュータ開発実施本部のWebサイト) |
2010年11月の「京」システムの3264コアのシステムでの測定やBlue Gene/Qプロトタイプの測定のようにごく小規模のシステムでの試験的な測定結果がTop500に登録されることはあるが、全体の8割というようなシステムでの測定結果が登録されたことは例が無いと思われる。LINPACKのチューニングを行い、性能を測定するには少なくとも2~3週間程度はシステムを占有する必要があるので、通常はフルシステムが完成してからの測定になる。
80%の計算ノードで測定値を出したのは、10~20PFlopsを目指す米国のBlue Waters、Sequoia、Titanなどのシステムが結果を出してくる前となる2011年6月のTop500に間に合わせて1位を取るためのウルトラCではないかと思われる。しかし、何にしても1位を取ったのと逃がしたのでは大きな違いで、作戦勝ちということであろう。
この「京」コンピュータであるが、富士通がこのシステムのために開発したSPARC 64VIIIfxという8コアのSPARCプロセサが使われている。今回のシステムが548,352コアということは68,544チップであり、1筐体に96チップが搭載されているので、714筐体のシステムということになる。
消費電力は9898.56kWとなっており、0.825GFlops/Wの効率である。消費電力としては第3位のJaguarシステムの7MWより40%大きい電力であるが、LINPACK性能はJaguarが1.76PFlopsであるのに対して「京」コンピュータは8.16PFlopsと4.6倍あまりの性能を出しており電力効率は3倍以上高い。また、Top500 2位のGPUを多用している中国のTianheは消費電力4.04MWで2.566PFlopsであり、効率は0.635GFlops/Wである。つまり、「京」コンピュータはGPUベースのシステムより電力効率が高い。
この高効率に大きく貢献しているのが、富士通がこのシステムのために開発したSPARC 64VIIIfxプロセサである。8コアで2GHzのクロックで動作し、128GFlopsのピーク演算性能を持っているが、消費電力は58Wと小さい。また、富士通はSPARC 64VIIIfxプロセサの計算ノード間を接続するICCというインタコネクトチップもこのシステム用に開発しており、計算ノードはこの2種のカスタムチップとDRAMだけで出来ているというシンプルで効率の良い構成となっている。

|
|
「京」コンピュータのシステムボード(左)とCPUウェハ(右)。システムボード左端の4個の水冷LSIがICC、中央の4個の水冷LSIがSPARC 64VIIIfx |
SPARC 64VIIIfxプロセサは、従来のSPARCアーキテクチャをスパコン向けに拡張したHPC-ACEと呼ぶアーキテクチャとなっている。SPARC 64VIIでは浮動小数点演算ユニットは64ビットの倍精度の浮動小数点の積和演算(FMA:Floating point Multiply Add)を2命令並列に実行していたが、SPARC 64VIIIfxプロセサではこれをSIMD拡張し、各命令が2つの積和演算を実行し、全体では1サイクルに4つの積和演算が実行できるようになっている。そして、浮動小数点レジスタの数を32個から256個に拡張して、ループ内の処理が複雑な場合でもほとんどの場合はレジスタ数が不足することが無いようにしている。

|
|
上が従来のSPARCの浮動小数点演算系の構成。積和(FMA)演算器が2個でレジスタは32個。下がHPC-ACEの浮動小数点演算系の構成。各命令で2個の積和演算が可能となり、レジスタも合計256個に拡張 |
また、キャッシュにも工夫が施されている。キャッシュはプロセサ内部の小容量の高速メモリであり、そこに何を入れるかはハードウェアが制御しソフトウェアはデータの出し入れに関与する必要はない。これは一般的には便利であるが、入れておきたいデータが追い出されてしまい、それを再度メモリから読んでくるために時間が掛り性能が下がってしまうという問題も発生する。
これに対して、SPARC 64VIIIfxではキャッシュを2つの領域に分割し、どちらの部分にデータを格納するかを指定できるセクタキャッシュと呼ぶ機能を持たせている。そして、キャッシュから追い出されては困るデータは一方の領域に入れ、一般的なデータは他方の領域に入れるようにする。このような構成とすることにより、一般的なデータのキャッシュへの読み込みで重要なデータが追い出されてしまうことを避けることが出来るようになっている。
「京」コンピュータの計算ノード間は、富士通がTofuと呼ぶ専用の高速ネットワークで接続されている。Tofuでは12ノード(図ではPと表記)を1つのまとまりとし、この12ノードは次の図のように接続されている。そして、この図では右下のノードだけにしか書かれていないが、全てのノードが赤線で書かれたX、Y、Zの+/-方向の接続を持っている。そして、隣接するグループ内の対応する各ノードのX+とX-を接続するというように接続して、3次元トーラスを構成する。この構成は12個の3次元トーラスがあり、それらが各12ノードグループのところでこの図のように黒線のリンクで相互に接続されていると考えることもできる。

|
|
「京」コンピュータ12ノードグループ。黒線はグループ内接続、赤線はグループ間接続を表す |
ICCチップはSPARC 64VIIIfxプロセサとの接続と合計10本の5GB/sの双方向リンクを持っている。そのうちの4本のリンクを上の図の12ノートグループ内の黒線の接続に使い、残りの6本をX、Y、Z方向の+/-の接続に使用している。各計算ノードは128GFlopsの演算性能に対して出入りの合計で100GB/sのバンド幅の接続を持っており、通信バンド幅と演算性能の比は0.78B/Flopと非常に高バンド幅の接続となっている。
LINPACKではあまり通信バンド幅は必要ないが、「京」コンピュータはこのようにスパコン向けに最適化された設計となっており、ピーク演算性能に対して93.03%という高いLINPACK性能を実現している。GPUでピーク演算性能を稼いでいるTop500 2位のTianheのLINPACK性能のピーク演算性能比率は54.6%であり、「京」コンピュータと同様に汎用プロセサと3次元トーラス接続を使っているTop500 3位のJaguarシステムでもその比率は75.5%であるのに比べて非常に高い演算効率を実現しているシステムである。
また、強力なTofuインタコネクトは通信量の多いアプリケーションに対しては威力を発揮するはずであり、LINPACKだけでなく、各種の実アプリケーションでの高性能の達成が期待される。