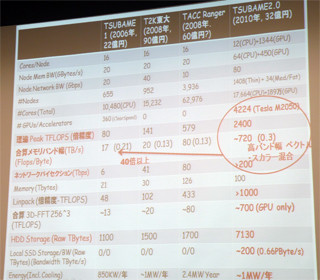
ピーク2.4PFlopsと国内では断トツの性能となるTSUBAME2.0であるが、TSUBAME2.0はGPGPUでピークFlopsをかさ上げした単なるLINPACKマシンではない。

|

|
|
TSUBAME2.0の巣となる東工大GSIC |
TSUBAMEの生みの親である松岡教授 |
OSはLinux+XenがベースだがWindows HPCサーバも利用可能
計算ノードのOSはSUSEのSLES 11の上にXenを載せるという構成が標準となる。この仮想マシン上でCent OSやMicrosoftのWindows HPCサーバを動かすことができる。また、Windows HPCサーバのユーザが多ければ、コンフィギュレータが一定数のノードでWindows HPCサーバをコールドブートして、仮想化のオーバヘッドを省くこともできるようになるという。
そして、アプリケーションの実行環境としては、OpenMPIによるMPI分散処理が基本であるが、他のMPIもサポートするという。したがって、並列処理を行うスパコン用のプログラムとしては、まず、MPIで処理を計算ノードに分散し、各計算ノードでは、演算負荷の高い部分はGPGPUのSingle Instruction-stream Multiple Data-stream(SIMT)モデルで並列処理を行うことになる。
GPGPUのプログラミング
GPGPUのプログラミング環境としては、一番、環境の整備されているNVIDIAのCUDAがメインとなるが、GPGPUプログラミングになじみの薄いユーザも多いので、Portland Group(PGI)のPGI FORTRANも提供するという。また、大学のセンターでは幅広いユーザをサポートする必要があるので、OpenCL環境も提供するという。
CUDAでは同じ命令列の多数のスレッドを並列に実行するSIMTモデルで実行を行い、1~3次元のスレッド配列をスレッドブロック、そしてスレッドブロックの1~2次元の配列をグリッドと呼んでいる。そしてCPU側のプログラムからは、このグリッド単位でGPGPUに実行を指示する。その際、1個のスレッドブロックは1個のStreaming Multiprocessor(SM)で実行される。M2050ボードに使われているFermi GPGPUの場合、1チップに14個のSMが集積されており、同時に14個のスレッドブロックを実行することができる。
TSUBAM2.0の計算ノードは3枚のM2050ボードを搭載しているので52個のSMがあることになる。CUDAの1つのグリッドに含まれるスレッドブロックを3枚のM2050のSMに割り振ることはでき、1つのホストプログラムから3枚のM2050ボードを動かすことはできるのであるが、3枚のボードのデバイスメモリは別々であるので、別ボードに割り当てられたスレッドブロックのスレッド間では共通メモリを使ったデータの参照ができない。
一方、同じボードに割り当てられたスレッドブロックのスレッド間では、従来通り、データの参照が可能であり、プログラミング上、区別が必要となる。このため、CPU側でそれぞれのGPGPUを動かすプロセスを走らせる方が分かり易いのではないかと思われる。このようにしても、Westmere-EP CPU2個で合計12コアもあるので、各GPGPUの制御のために1コアずつ割り当てたとしても問題にはならないであろう。
3枚のボードはPCI Express 2.0で接続されており、同じアドレス空間上に存在するので、ハードウェアとしてはGPGPUとGPGPUのデバイスメモリ間でDMA転送を行うことが可能であるが、そのようなデバイスドライバは存在せず、現状ではGPGPUから一旦、CPUのホストメモリに転送し、改めて別のGPGPUのデバイスメモリに転送するという手順が必要となってしまう。
SIMTモデルでプログラムを作ればGPGPUを有効に利用することができるのであるが、すべてのユーザがこのようなプログラムを作ってくれるとは限らない。現在のTSUBAME1.2でどの程度、GPGPUが利用されているかを聞いたところ、Job数では全体の数%程度とのことであった。Job数のカウントではCPUをチョコっと使うJobも、多数のGPGPUを長時間使うJobも1個に数えてしまうので正確な測定とは言えないが、それでも、まだ、GSICセンターではGPUを使いこなしているユーザは少数で、これを増やさないとTSUBAME2.0の4224枚のM2050ボードが泣いてしまう。
GPGPUの性能を引き出す
東京工業大学(東工大)はTSUBAME1.0でClearSpeedの浮動小数点演算アクセラレータを付け、TSUBAME1.2でNVIDIAのTesla 10 GPGPUを増設し、アクセラレータを効率的に使う研究開発を行ってきている。
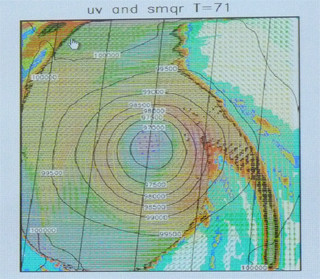
東工大の青木教授のグループは、気象庁が次期気象モデルとして開発しているASUCAプログラムをGPGPU向けにチューニングを行いTSUBAME1.2で約15TFlopsと地球シミュレータと同等の性能を達成し、TSUBAME2.0では150TFlopsを達成できると見込んでいる。気象コードは、水分が水蒸気、雲粒、雨滴などと変わると支配方程式が変わり、重力多体問題や第一原理計算に比べるとピーク性能に対する実効性能が出ないコードで、Jaguarで気象の標準的なコードであるWRF(Weather Research and Forecasting)を実行した場合、50PFlopsしか出ないという。プログラムが違うので正確な比較ではないが、GPGPUで実行するのが難しいと思われる気象コードでJaguarを3倍上回る性能というのは大したものである。
もっとも、このアルゴリズムのチューニングには東工大の青木教授のグループと気象庁が協力して1年掛かったとのことであり、単にASUCAのコードをCUDAコンパイラでリコンパイルすれば済むという話ではない。しかし、気象コードでも頑張れば性能が出るということは、GPGPUは一部のアルゴリズムだけではなく、かなり広範な問題に対してもやり方によっては高い性能が出せるという可能性を実証したものと言える。現在は、熟練したプログラマが工夫をする必要があるとしても、経験が蓄積されてくれば自動化が進むのがコンピュータの歴史で、その点で、新しい計算装置であるGPGPUを使いこなすという東工大のチャレンジに期待したい。