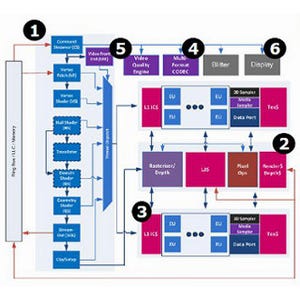
D-Cache Associativity(グラフ83~88)
ついでにAssociativityも確認してみる。こちらはNear/Farの区別は当然ないので、単にL1/L2について4種類のアクセスパターンで比較するだけである。
まずL1のForward(グラフ83)。こちらだとHaswellもIvy Bridgeと同様、4 PointでLatencyが増えるあたりを見ると、I-CacheのAssosiativityに何かしらあるのか、もしくは妙な形でDecoded μOp Cacheが動作していたのかもしれない。それはともかく、最初の4 Pointを超えるとちょっとLatencyが増えるが、これはHaswellが大分Latencyが少なく、やはりTag RAMの検索が高速化していることが伺える。ただ16 Pointを超えるとL1 Missと判断するためかL2 Accessになるようだが、こちらでは明らかにHaswellがIvy Bridgeより5cycle前後Latencyが増えているのが判る。この傾向はBackward(グラフ84)、Random(グラフ85)共に共通で、そういう特性を持っているのは間違いない。
んではL2は? というとForwadがグラフ86、Backwardがグラフ87であるが、こちらも特性は良く似ている。Random(グラフ88)では4 Pointを超えると完全にCache Missと判断するようでグラフの形もかなり崩れているが、16 Point以降ではHaswellの方がLatencyが大きくなっている。要するに、L1にせよL2にせよ、単体のアクセスの際のLatencyは低く抑えられているが、L1/L2 Missの判断が入った際のLatencyがIvy Bridgeより大きめ、という事なのかも知れない。
次ページ:RMMA 3.8 - Average RAM Latency