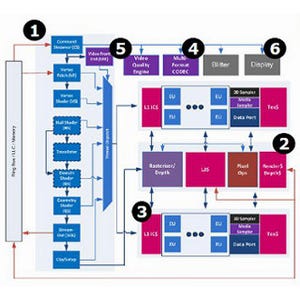
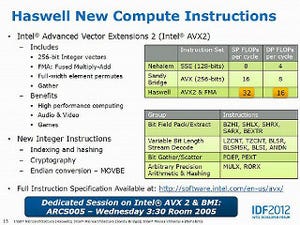
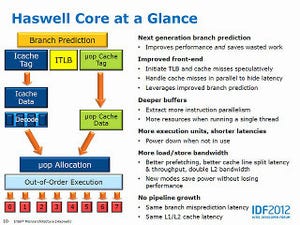
Maximum RAM Bandwidth(グラフ76~78)
L1~L3の帯域はこれでよいとして、Memory Accessの方をもう少し。グラフ76~78は、SSE2のPrefetch命令、及びH/Wを使ったBlock Prefetch1/2でRead/Write/Copyを行なった結果をまとめたものである。

|
まずSSE2のPrefetch命令を使ったケースがグラフ76だが、面白い事にPrefetchを使うとHaswellの場合、ReadよりもWriteの方がスループットが高いという、他に例の無い結果になった。またHaswellのReadは、Ivy Bridgeよりもややスループットが落ちるという不思議な結果になっているのも判る。もっともこの結果そのものは、RMMTの結果(グラフ1・2)とも符合するもので、単にMemory Controllerだけの問題ではなく、SSE2などを使う限りはLoadのBandwidthは倍にならず、むしろオーバーヘッドが増える結果として微妙(5.5Bytes/cycle→5Bytes/cycle)に性能が落ちる事になっているようだ。このあたり、例えばAVX2命令を使うとどこまで上がるかはちょっと興味あるが、今回はそれを試すことはできなかった。

|

|
ちなみにBlock Prefetchを使うとReadはIvy BridgeとHaswellでほぼ同等だが、スループットは3Bytes/cycleでほぼ同等、一方WriteはHaswellが5.8Bytes/cycleほど、Ivy Bridgeが5.1Bytes/cycleほどで一定となっており、HaswellではかなりWritebackに関して性能を改善していることが見て取れる。