Intel Optimized SMP LINPACK Benchmark package Version 11.0.3(グラフ29~30)
Intel
http://software.intel.com/en-us/

|

|
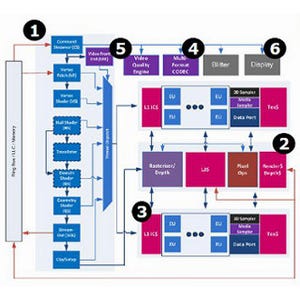
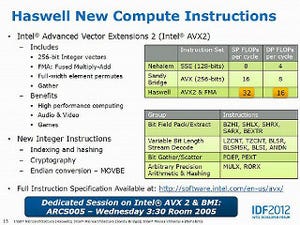
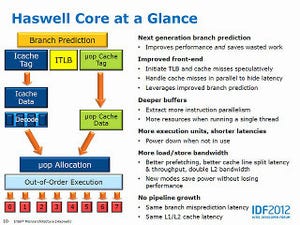
久々のLINPACK。今回はIntel MKL(Math Kernel Library)が11.0 Update 3のものを使っている。MKL 11.0からAVX2をサポートしている関係で、Haswellではやや性能が伸びることが期待できる。結果もこれを反映しており、アベレージ性能(グラフ29)・ピーク性能(グラフ30)共に6~12GFLOPSほど上回る結果になった。逆に言うと、演算性能が倍にも関わらず実際の性能差はこの程度、という言い方もできる。理由として考察できるのは、L1以外のボトルネックである。AVX2をフルに生かすためには、単にL1だけでなく全般的に32Bytes/cycleの帯域がないとそこがボトルネックになるわけだが、Haswellではグラフ13からも明らかな通り、帯域が倍なのはL1のみでそこからはIvy Bridgeとさして帯域が変わらない。一方LINPACKではL1に収まる程度のサイズだとそもそも性能が出ないので、もっと大規模なサイズにしてやる必要があり、するとL2/L3やメモリがボトルネックになるという、判りやすい構図だ。とはいえそれでも帯域にまだゆとりがあり、結果として性能が向上したのはすばらしいとは思う。