今回からは、SQL Data Warehouseのアーキテクチャを詳しく紹介します。SQL Data Warehouseのアーキテクチャを理解すれば、データベースのチューニングなども役に立ちます。今回のテーマは「テーブルの分散」に関わるSQL Data Warehouseのアーキテクチャです。
SQL Data Warehouseでは、他のデータベースと同様にCREATE TABLE文を使ってテーブルを作成できます。例えば、以下のようなCREATE TABLE文のSQLでSQL Data Warehouse上にテーブルを作成可能です。
CREATE TABLE test(col1 INT,col2 VARCHAR(20),col3 VARCHAR(20));
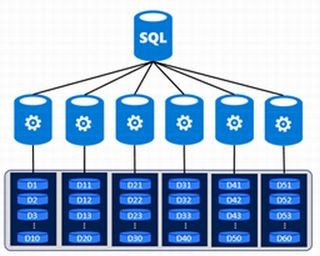
上記のようなCREATE TABLE文のSQLでテーブルを作成し、データの投入を行った場合、データは60のストレージ(ディストリビューション)に分散されて格納されます。データが分散されて格納されるので、「分散テーブル」と言われています。
分散テーブル
SQL Data Warehouseは複数の計算ノードへ処理とデータを分散することで、処理の高速化を実現する超並列処理(MPP)分散データベースです。データはそれぞれ異なる60のストレージへ格納されます。
60のストレージへのデータの分散配置方法は、2017年6月時点で2種類用意されています。 それがこの2つです。
- ROUND ROBINによる分散
- HASH KEYによるハッシュ分散
先ほど紹介したようなCREATE TABLE文(分散方式の定義がないCREATE TABLE文)の場合は、ROUND ROBINによる分散になります。
ROUN ROBIN分散による均等分散
テーブルの分散方式をROUND ROBIN分散に指定する場合は、テーブルを作成する際のCREATE TABLE文で分散方式を定義しないか、あるいは、WITH句の中に「DISTRIBUTION=ROUND_ROBIN」を指定します。
CREATE TABLE test_round_robin (
col1 INT,
col2 VARCHAR(20),
col3 VARCHAR(20)
)
WITH(
DISTRIBUTION = ROUND_ROBIN
);ROUND ROBINによるデータ分散は非常に単純で、60のストレージに対してラウンドロビン方式で順番にデータが配置されていきます。例えば、6000万件のデータを投入した場合、各ストレージに100万件ずつデータが格納されることになります。
HASH KEYによるハッシュ分散
ハッシュ分散は、ハッシュ分散アルゴリズムを使用して、テーブルに投入されるデータを60のストレージへ分散し格納する方式です。テーブルにはいくつもカラムが存在しますが、そのうちのどれか1つのカラムを HASH KEYとして指定することで、そのカラムの値からハッシュ値を計算し、データをどこのストレージへ配置するのか決定します。

|
ハッシュ分散方式でテーブルを作成するには、CREATE TABLE文のWITH句に「DISTRIBUTION=HASH(<カラム名>)」を指定します。
CREATE TABLE test_hash (
col1 INT,
col2 VARCHAR(20),
col3 VARCHAR(20)
)
WITH(
DISTRIBUTION = HASH(col1)
);この例ではtest_hashテーブルのcol1というカラムをHASH KEYに指定し、ハッシュ分散をしています。
ハッシュ関数を使ったハッシュ分散によるデータの分散
SQL Data Warehouseは60のストレージへデータを分散格納させますが、ハッシュ分散では、先ほどの説明の通り、ハッシュ関数を使って60のストレージに対するデータの配分先を決定します。
このハッシュ分散によるデータ分散方式の最大の利点は、同じデータは同じストレージ上に格納されることです。この特徴をうまく利用すると、結合などの処理でストレージ間の「データ移動」を大幅に減らし、処理を高速化できます。こうしたハッシュ分散を利用したチューニングに関しては、今後本連載でチューニングについて説明する際に詳しく解説する予定です。
データ移動
ROUN ROBINによる分散にしても、HASH KEYを利用したハッシュ分散にしても、60のストレージへデータは分散配置され、DWUに応じた、複数の計算ノードで分散処理される点に違いはありません。計算ノードは60のストレージから、いくつかのストレージが割り当てられており、割り当てられているストレージ以外のデータに直接触ることはできません。
では、もし結合などの処理で、計算ノードが他の計算ノードに割り当てられているストレージのデータを必要とした場合はどうなるのでしょうか?
例えば、売上テーブルと顧客テーブルが存在しており、売上テーブルは注文番号でデータをハッシュ分散し、顧客テーブルは顧客番号でデータをハッシュ分散して格納している場合を考えてみましょう。

|
売上データと顧客データをSQL Data Warehouseに格納 |
売上テーブルを顧客テーブルに顧客番号で結合するクエリを実行した時などは、売上テーブルと顧客テーブルは顧客番号で結合するにもかかわらず、各テーブルが異なるHASH KEYで分散されているので、顧客番号が同じでも結合に必要なデータが異なるストレージに配置されます。
この時、SQL Data Warehouseでは各計算ノードで結合に必要とする売上テーブルのデータを、他の計算ノードに割り当てられているストレージから移動させる「データ移動」と呼ばれる動作を行います。言い換えると、売上テーブルのデータを顧客テーブルと同じ、顧客番号でデータ分散し直すという動作です。

|
テーブル結合時にHASH KEYが異なるため、「データ移動」が発生 |
「データ移動」の動作を発生させるSQL文は以下のようになります。
--売上テーブル
create table sales(
SalesOrderID int, --注文番号
OrderDate datetime,
CustomerID int, --顧客番号
SubTotal money
)
with(
DISTRIBUTION = HASH(SalesOrderID)
);
--顧客テーブル
create table customers(
CustomerID int, --顧客番号
TerritoryID int,
AccountNumber int,
CustomerType nchar(1),
ModifiedDate datetime
)
with(
DISTRIBUTION = HASH(CustomerID)
);
--顧客番号で結合(データ移動が発生)
select * from sales s inner join customers c
on s.CustomerID=c.CustomerID;「データ移動」はSQL Data Warehouseの内部の負荷が非常に高い処理なので、極力、この「データ移動」を発生させないことが重要になります。この例では、売上テーブルは注文番号ではなく、顧客番号でHASH KEYを指定すれば、この「データ移動」を回避できます。
山口 正寛
1984年生まれ。大阪府出身、東京都在住。データベースエンジニア。SQL Server、Oracle、MySQL、PostgreSQLなどのデータベースで、小規模から大規模な案件まで数多く経験。現在ではクラウドの流れに逆らうことなく、「データベース×クラウド」をキーワードに案件対応、セミナー活動、執筆活動など幅広く活動中。株式会社システムサポート所属。