OpenACC化したコードの性能は?
ということで、並列実行ができる部分を個別にparallel loop指定するか、まとめてkernels指定することにより、GPUに処理をオフロードするコードが作れるが、性能はどうであろうか?
図12はCPUでのマルチスレッドの実行とOpenACCでGPUにオフロードした場合の性能を比較したものである。

|
|
図12 CPUでの実行とOpenACCでGPUオフロードした場合の性能比較 |
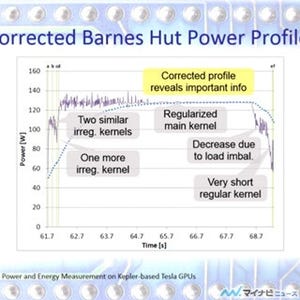
CPUで1コア1スレッドで実行した場合の性能を1.0とすると、CPUのコア数を増やすと、コア数比例ほどではないが性能は上がり、6コアで3.5倍の性能になる。一方、OpenACCを使ってGPUにforループの処理をオフロードすると、性能は0.6と1コアの60%の性能しか出ない。ここで、やっぱりOpenACCではダメだとあきらめてしまう人があるが、もう、一頑張りすることが重要という。
図13は、NVPROFというツールで、OpenACCで生成したコードの実行状況を調べた画面である。これを見ると、49.59%の時間がHost(CPU)からDevice(GPU)へのCUDA memcopy、45.06%の時間がDeviceからHostへのCUDA memcopyに使われており、実行時間の大部分がCPUとGPU間のデータ転送で、2つのカーネルを実行している時間は、それぞれ2.95%と2.39%でしかない。

|
|
図13 図9のOpenACCのコードの実行をNVPROFで測定した結果 |
図14は、同じ実行状況をNVIDIAのVisual Profilerで出力したもので、一番上の縞がDrive APIの動作、次の縞がHtoDのmemcopy、その次がDtoHのmemcopyである。その次の細いまばらな縦縞がGPUの動作時間で、それに続く2つの縦縞が、内訳のそれぞれのカーネルを実行している時間である。

|
|
図14 実行状態をVisual Profilerで表示したもの |
図14に見られるように、HtoDの長いmemcopyの後に短時間のカーネル1の実行があり、切れ切れのDtoHのmemcopyがある。カーネル2の実行も同様であることがわかる。
このような実行になるのは、それぞれのカーネルの実行に当たり、AとAnewという配列をCPUからGPUに転送し、GPUでのカーネルの実行が終わるとAとAnewをCPUに転送しているからである。

|
|
図15 カーネル実行に伴うCPUとGPU間のメモリのコピーの状況 |
Anewはテンポラリな変数で、転送は必要ないのであるが、コンパイラは間違った結果を出すわけにはいかないので、安全サイドのコードを生成するので、このような結果になっている。
第3ステップはデータ転送の最適化
ここで、動作の分かっているプログラマが、データの転送の要否をコンパイラに教えてやれば、無駄なmemcopyを省いてOpenACCで生成したコードの性能を上げることができる。
このコピーの要否を教える基本的なメカニズムが図16に示すData Regionである。

|
|
図16 データのコピーの要否を教えるData Region |
図16のように、#pragma acc dataと書くと、その次の{ }の中の部分ではGPUメモリ上の配列はGPUに留まり、{ }の中に複数のカーネルがあっても、配列は共通に使われるということを意味している。つまり、第1のカーネルで計算したAnewの配列は、第2のカーネルでもそのまま使えるということを指定できる。
また、dataの指定は、図17に示すように、さらに詳細な指定ができる。copy( )と書くと、( )内に書かれた配列に対して、GPUにメモリ領域を確保し、data regionに入るときに、CPUからGPUにmemcopyを行う。また、data regionを出るときにGPUからCPUにmemcopyを行う。これは安全なデフォルトの動作とほぼ同じである。
しかし、copyin( )と書くとGPUメモリの確保とCPU→GPUのmemcopyだけで、終了時のGPU→CPUのmemcopyは行わない。また、copyout( )はこの逆で、GPU→CPUだけでCPU→GPUのmemcopyは行わない。
そして、create( )はGPUメモリの領域確保だけ、present( )は、その配列はすでにGPUメモリ上にあることを示す。

|
|
図17 data節にはさらに細分化した取扱いを記述できる |
また、presentorcopy[in|out]と書くと、presentの場合は何もせず、その配列が存在しない場合はcopyinあるいはcopyoutを行う。presentorcreateは、配列が存在しない場合だけ領域を確保する。
領域の確保であるが、Fortarnの場合は行列の定義でサイズが分かるが、Cの場合は引数として渡される場合などはサイズが分からない場合がある。このため、図18に示すように、data節で配列のサイズを指定したり、配列の中のコピーが必要な部分の先頭と要素数を指定して、必要な部分だけをコピーさせることができる。
この機能はヤコビ法の例では使っていないが、配列全体ではなく、一部のコピーで済む場合に指定すれば、転送量を減らすことができる。

|
|
図18 data節では、コピーが必要な部分を指定することができる |
図19では、配列Aはdata regionに入るときにGPUに領域を確保し、CPUからのコピーが必要で、data regionから出るときにCPUメモリへのコピーが必要と定義し、配列AnewはGPUメモリに領域を確保するだけで、CPUメモリとの転送は指定していない。
なお、配列Aはカーネル1の入力となり、カーネル2で更新されているが、data regionの中ではGPUメモリに存在したまま使われるので、次回のカーネル1の実行では、前回にカーネル2が書き込んだ値が使われ、正しい動作となる。
この指定により、Anewのコピーは不要になり、Aもdata regionに入るときと、出るときだけにコピーを行うだけで済み、データ転送は大幅に減少する。

|
|
図19 全体を1つのdata regisonとして、配列Aはcopy、Anewはcreateと指定 |
このように指定したコードの実行状況をVisual Profilerで見ると図20のようになる。図20では、memcopyは極めて短い時間で、2つのカーネルがほとんどの実行時間を占めていることがわかる。

|
|
図20 data節で転送の要否などを指定したコードの動作状況 |
その結果、実行性能は図21のようになり、OpenACCコードの実行性能はシングルスレッドCPUの16倍を超え、図12の0.6倍とは様変わりの性能向上が得られる。

|
|
図21 Memcopyの時間がほとんどゼロとなり、CPU1コアに比べて16倍以上の性能を達成 |
時として、1つのdata regionでの計算結果を次のdata regionに渡したい場合がある、このような場合にはpresent( )指定を使うことにより、無駄なコピーを省くことができる。
図22の右側の例は、メインで関数laplace2Dをcopy(A)のregionで呼び出し、laplace2Dの中ではAをpresentと指定してコピーを不要としている。

|
|
図22 present指定を使って、異なるdata region間で無駄なコピーを省く |