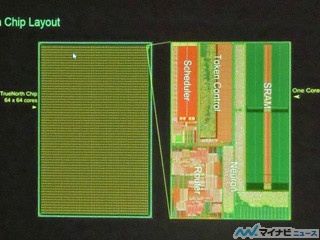
ニューロン計算はメモリネックになるので、IBMのTrueNorthやマンチェスター大学のSpiNNakerなどの専用ニューロチップは非ノイマン型のアーキテクチャをとるものが多いが、PEZY-SCでは、特定のPEだけがアクセスできれば良いデータはローカルメモリに置き、全体的なアクセスが必要なデータは外部のDDR4メモリに置くという方法で上手く処理することができた。

|
|
PEZY-SCへの実装ではローカルメモリを上手く使うことでメモリボトルネックを軽減している |
シナプスの計算は、256K個の顆粒細胞について、その出力Xjとプルキンエ細胞のシナプスの結合重みWij(iはプルキンエ細胞のインデックス)を掛けて、それらの合計を求めるという積和計算となる。

|
|
シナプス入力の計算では |
それぞれのPrefectureに8個のPC(プルキンエ細胞)を担当させ、L3キャッシュに8PC分のWijとXj格納した状態でWij *Xjをj=0~256Kを計算する。これを1024スレッドで実行し、1024個の部分的な積和を作り、それをCity単位と、Village単位でリダクションしてSyn(i)を作る。このようにすれば大部分のメモリアクセスはキャッシュで納まる。

|
|
チップの1/4のPrefectureに8個のプルキンエ細胞を割り当てる。そして各レベルのキャッシュを有効に使って、メモリアクセスを減らして性能を上げる |
そして、スパイクはビットマップ形式で64ビット変数に64ニューロン分を格納して、メモリ消費を減らしている。

|
|
スパイクの有無は、ビットマップで64ビット変数に64入力分を格納して、メモリ消費を抑える |
そして、シナプス入力の積和計算において、重みが定数の場合は単にスパイクの数を数えればよく、それは次のようなコードで、64ビット変数の中に"1"がどれだけあるかを数えればよい。

|
|
トリッキーなコードであるが、64ビットの中で"1"が何個あるかを高速に数えられる |
前の説明では第2層と第3層の接続はチップ内のキャッシュの間の転送だけであるかのように書いたが、プルキンエ細胞は、数100μm程度の範囲の顆粒細胞から信号を受け取っており、隣接チップ間の通信を必要とする信号もある。このような大きな遅延を隠すために、スパイク配列をダブルバッファリングして、計算とMPI通信をオーバラップさせて実行時間を短縮している。

|
|
スパイク配列をダブルバッファリングして、通信と計算をオーバラップさせて実行時間を短縮する |
そして、スパイクの通知を毎サイクルではなく、Nサイクルまとめて行い、通信回数を削減する。

|
|
さらに、N回分の通信をまとめて行い、通信時間を削減 |
これらの性能改善を施した結果、6秒分のシミュレーションを4.8秒で終えることができるようになり、リアルタイムのシミュレーションが可能になったという。しかし、小脳プログラムはメモリバウンドの計算であり、これらの性能改善を行った結果で、演算の実行効率は2.6%(約68GFlops)であったという。

|
|
チェッカーパターンを眼前で動かして、それを追う目の動きのシミュレーション。6秒のシミュレーションが4.8秒で計算できるようになった。 |
4月上旬のShoubuは80%程度しか動いていなかったが、6月7日には全系での動作を確認し、72mm×70mmの小脳が扱えるようになったとのことである。そして、将来の計画としては、PEZY-SC2を使う次世代機(今回の10倍の性能となると仮定して)で1000億ニューロンの人間の小脳のリアルタイムシミュレーションに挑む。メモリバウンドであるので、磁界結合の超高帯域のメモリに期待するところ大である。また、数が膨大な顆粒細胞の計算にはメニーコアのPEZY-SC2は非常に有利だが、それ以外の数の少ない細胞の計算に使うのはもったいない。そこで、それらはPEZY-SC2に搭載予定のMIPSコアで計算することにすれば、全体の計算をバランスよく進めることが可能になると考えている。
その次のエクサの時代のターゲットは、人の全脳シミュレーションである。そうなると、脳機能の一部を人工脳で補完し、例えば、事故などで脳そのものの一部を欠損してしまった人や、脳梗塞で麻痺してしまった人、加齢により脳機能そのものが低下してしまった人達が、健康な人と同じように歩いたり、体を動かしたりすることもできるようになる、と夢は膨らむ

|