ディープラーニングのモバイルイメージングへの応用を図るモルフォ
モルフォも東京大学(東大)発のベンチャーで、スマートフォン(スマホ)などのカメラで撮影した画像の処理ソフトに強みをもっている。モルフォはエンドユーザには直接製品を販売していないが、スマホ用のSoCを作るメーカー、携帯電話の端末機器を作るメーカー、あるいはスマホのサービスを提供する通信事業者にソフトウェアをライセンスしたり、保守サポートを提供したりするというビジネスを行っている。モルフォのソフトウェアによる手振れ補正は高く評価されており、Samsung、LG、Motorola、京セラ、Huaweiなどで採用されているという。
|
|
|
モルフォのディープラーニングへの取り組みについて講演する大熊顕至氏 |
モルフォのソフトウェアは、2006年の創業以来、累計では11億ライセンスを超え、特に最近の2013年以降だけで5億ライセンスと急速に伸びているという。
このモルフォのモバイルイメージングに対するディープラーニングについて、同社のシニアリサーチャの大熊 顕至氏がNVIDIAのディープラーニングフォーラムで講演を行った。同社はこれまでディープラーニングを手掛けていることを発表しておらず、これが最初の発表であるという。
デジタルカメラ(デジカメ)やスマホの写真が大量になってくると、どのような写真がどこに入っているのか分からなくなってしまう。このため、モルフォは写真画像を解析し、自動的にタグ付け行うシステムを開発している。

|
|
ディープラーニングを使いスマートフォン上で、画像を解析し、自動的にタグ付けを行う |
現在、SamsungのGalaxy Note4上で、GPUは使わずCPU上でシングルスレッドで認識ソフトを動かして7枚/秒のタグ付け性能を得ているという。ディープラーニングを実用化するためには、学習のための大量のデータを集めること、シンプルなモデル/ネットワークとすること、そして効率的な学習・認識とすることがポイントであるという。
学習はサーバを使っても良いが、実際のモバイル機器での認識では、使える計算リソースや電力が少ないので、シンプルなモデル/ネットワークとすることは不可欠であるという。

|
|
学習のために大量のデータを必要とするのは当然であるが、モバイル機器では使用できる計算リソースや電力が制限されるので、シンプルなモデル/ネットワークとすることが重要である |
大量の学習データの収集であるが、ラベル付けのコストが大きな問題であるという。例えば、1200万画像にそれぞれ1000ラベルを付けると、120億のラベルを付けることになり、1ラベル1円でも膨大なコストが掛かる。
また、画像を分類するたけで良いのか、顔などの物体を検出するのか、さらに対象の部分だけを抜き出すセグメンテーションを行うのかで、コストは大幅に違ってくる。

|
|
何枚の画像にいくつのラベルを付けるか、どこまでの精度で対象を指定するかでラベル付けのコストは大幅に違ってくる |
次の図のように、家具の下にテーブル、いす、動物の下に犬、猫などのカテゴリを階層的に書き、入力画像ごとにそのカテゴリが含まれていれば「+」、なければ「‐」を付けるという方法で、ラベル付けのコストを減らす方法が提案されており、Amazon Mechanical Turkを使って2万枚、200カテゴリのラベル付けのコストを1/6に下げることが出来たという結果が報告されているという。

|
|
階層的なカテゴリを作り、入力画像にそれぞれのカテゴリが含まれている場合は「+」、含まれていない場合は「‐」を付けるという方法で、ラベル付けのコストを下げる |
また、大量の入力画像をデータ補完で作るという方法も用いられる。色彩調整や切り取り、回転などの画像の加工で、Baiduはデータを約8万3000倍に増加させて学習をさせることで認識率を向上させたと報告されている。また、背景だけは本物を使い、通行人は色々な人間をCGで書き込んだデータを使うという論文もある。

|
|
入力画像を加工して、疑似的に新しい入力データを作って学習させて認識率を改善する |
このような入力データ作成の効率化の方法はあるが、データの収集とラベル付けはコストが掛かる。入力データを増やせば認識率は上がるが、その製品としてどれだけの精度が必要であり、どれだけのデータが必要かを判断するのは重要であるが、難しいという。
いずれにしても、ここ数年は半自動・半教師付き学習によるデータ収集の効率化を行うというやり方が使われると思われるが、その先は教師なしの完全自立型の学習になる可能性が高いと予測しているという。
シンプルなモデルという点では、2012年のILSVRCで優勝したAlexNetは15層(活性化関数も層に数えているので一般に言われる8層より多くなっている)で約6000万パラメタを持っていたが、2014年のGoogLeNetは40層(活性化関数を除くと22層)と層数は増えたがパラメタ数は約700万と大幅に減少し、シンプルになっている。

|
|
2012年のAlexNetは層数は少ないが、パラメタ(ニューロンへの入力の重み)は6000万と多かった。これに対して2014年のGoogLeNetは層数は増えたが700万パラメタに減り、同時にエラー率が大幅に減少している |
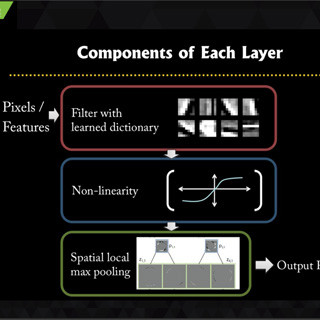
ニューラルネットの個々の部品はシンプルであるが、Convolutionフィルタの数、大きさ、ステップをどうするか、Poolingフィルタの大きさとステップ、何層のネットワークとするか、などなど、決めるべき事項は数多くある。開発しようとしているシステムに応じたシステムデザインが重要であるが、これらのパラメタの選択が性能や計算時間にどう影響するかは分からない点が多く、難しい問題であるという。

|
|
モデルの個々の部品はシンプルだが、この図に示すように、決定すべきパラメタは多くある。実現するデバイスに応じたモデルのデザインが重要 |
また、画像の学習時間も問題で、1000カテゴリ、1000万画像を、1台のPCにTitan Black GPUを付けたシステムで学習しようとすると、1週間以上かかってしまう。このため、学習を分割して複数台のPCやGPUを使って学習を効率化することが重要である。

|
|
1台のPCにTitan Black GPUを付けたシステムでは、1000カテゴリを持つ1000万画像の学習には1週間以上かかる。並列化で性能を上げることが重要 |
モバイルイメージングでは、撮る(Shoot)、見る(Show)を開発してきたが、探す(Search)を加えて新たな付加価値の創出を目指すという。サーチに関しては、シーン認識やタグ付けを、ディープラーニングを応用して開発していく。

|
|
モバイルイメージングではShootとShowに加えてSearchが必要になっており、シーン認識やタグ付けをディープラーニング技術を使って実現しようとしている |
今後の取り組みとしては、モバイルイメージングで本当に必要な機能、性能を実現する研究開発、多種多様な認識タスクの開発、シンプルで効率的なインタフェースの開発を行う。要素技術としては、学習や認識の高速化・効率化、多種の認識を行うモデル、動画対応などを行っていくという。

|
|
今後、実用に基づいた研究開発、多種多様な認識タスクの開発、よりシンプルで効率的なインタフェースの開発を行っていく。また、学習の効率化、認識タスクの多様化、さらに動画対応などを行っていく |
モバイルイメージングでは、よりよく撮るためにもディープラーニングは使えるのではないかと思うが、一方、筆者としては、大量の画像のサーチをモバイルデバイスで行わなければならない必然性はないのではないかと思う。まあ、スマホしか持っていない人には必要かもしれないが、その場合は、大量の画像はクラウドに置くことになり、やはり、スマホでサーチするというニーズがあるかという点は疑問である。