理化学研究所(理研)と理研ベンチャーのダナフォームは、共同開発したDNA増幅法「PEM(PCR Eprobe Melting)法」を用いて、既知の約6000万箇所の「一塩基多型(SNP;Single Nucleotide Polymorphism)」を検出するための人工核酸(プライマー/プローブ)の最適な配列をすべて計算し、そのうち約4000万箇所をカタログ化したと発表した。
一塩基多型(SNP)は現在までにヒトのゲノム上に疾病などとの関連が分かっているものは、未知のものを含め約6000万箇所あることが分かっており、そのほとんどが判明したと考えられているため今後は、これら既知のSNP情報をもとに、疾病関連SNPを同定する研究や診断に簡単に利用できるように基盤を整備することが求められている。
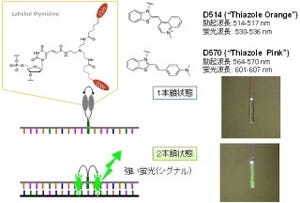
一方で医学利用の観点からは、SNPを高い精度で検出することが必要であり、PEM法は従来法とは異なり、SNPが密集した領域の遺伝子変異の有無も高い精度で簡便に検出することが可能だ。ただしPEM法に必要な短い人工核酸(プライマーおよびプローブ)の設計は、比較的容易ながら、検出しようとするSNPごとにプライマーとプローブの配列を検討する必要がった。
そこで今回、研究グループは既知のほぼすべてのSNPを検出するために最適なプライマーとプローブのセットをあらかじめ計算し、それをカタログ化することに挑んだという。
理研の大規模PCクラスタでデータ転送などの処理を最適化して並列処理を行った結果、他のSNPが非常に近くにあるなど、配列固有の理由でプライマーやプローブが設計できないSNPを除いた約4000万箇所についてプライマーとプローブのセットの配列情報を得ることに成功したという。
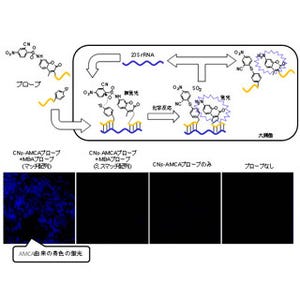
同データの総量は1.2TBで、得られた約4000万セットの配列情報は、ダナフォームのWebサイトにて無償で公開されているほか、PEM法のプライマーとプローブの設計を行った設計ソフトウェア「Edesign」も合わせて公開されている。
なお研究グループでは、今回、既知のヒトSNPの多くの部分をカバーするプローブとプライマーのセットの配列カタログが整備されたことで、PEM法の利便性が向上し、SNPに基づく個別化医療の実現に前進をもたらすと期待できるとコメントしている。

|

|
|
PEM法の概要 |
公開されたデータのイメージ |