4月22日、GLOBALFOUNDRIESは都内でプライベートセミナーを開催したが、これに合わせて記者説明会を行い、同社の動向と最新ロードマップについて説明を行った(Photo01,02)。

|

|
|
Photo01:主に説明を行われたSubramani Kengeri氏(Vice President, Technology Architecture Office of CTO) |
Photo02:最初の挨拶と補足説明などを担当された、島内秀氏(グローバルファウンロリーズ・ジャパン代表取締役) |
全体は3部構成になっており、まずは同社の現状について説明があった。同社は2014年1月に組織変更があり、CEOがAjit Manocha氏からSanjay Jha氏に代わった(Photo03)。Kengeri氏自身は既に同社で5年近くになるが、その前はTSMC、さらにその前はVirage Logicに勤務されており、いよいよGLOBALFOUNDRIESも本格的に半導体業界の転職ネットワークに組み込まれた感がある。

|
|
Photo03:顔写真の下のロゴは、Exective Teamの面々がこれまで経験してきた企業のものをまとめたもの |
それはさておき、結果として現在同社は前工程工場を3カ国に保持しており(Photo04)、今のところ生産量は好調に推移しているとする(Photo05)。この結果として、同社は現在ファンダリ業界でNo.2のポジションについているとする(Photo06)。

|

|

|
|
Photo04:言うまでもなくドレスデンは元AMDのFab30、シンガポールはChartered Semiconductorであり、ニューヨークのFab 8が同社としては初の新設拠点となる |
Photo05:ドレスデンおよびニューヨークはどちらも300mmのものとなる。年間最大800万枚は、もしニューヨークのFab 8が将来11万枚/月程度まで生産能力を上げると可能になる |
Photo06:もっともNo.1のTSMCは、2013年で年間1640万枚(200mm換算)のウェハを生産しており、当然売り上げの点でもTSMCにはまだ大きなギャップがある。2013年の売り上げで言うと、2~13位の全売り上げを足して、やっとTSMCと同等というあたりはなかなか壮絶である |
次が業界のトレンドである。GLOBALFOUNDRIESではここ数年、Technology Roadmapを加速することで先行するTSMCやIntelを追撃する姿勢を見せており、今回紹介する14nmは先行メーカーをキャッチアップできるマイルストーンとなるノードである(Photo07)。

|
|
Photo07:ちなみにこれはDesign Startの時期であって、量産開始とか製品完成の時期ではないので注意が必要 |
その14nm世代に向けた話であるが、まず大きなトレンドとして示されたのはこんな方向性である(Photo08)。ここでSuperPhone(要するに400ドル以上の価格のスマートフォン)とかPremium Tabletなどは引き続きマーケットの牽引役になるとする。14nmといった先端プロセスは、こうしたところに使われる事になるが、このSuperPhoneやPremium Tabletの占める割合は今後も増加していき、Middle Phone/Tabletまで含むと全体の半分近くになる、というのがARMの予測である(Photo09)。

|

|
|
Photo08:これはARMによる、今後のトレンドに関する説明 |
Photo09:言うまでも無く、これに伴いVoice/Feature Phoneはどんどんそのシェアを落としてゆく事になる |
さて、ここからはSynopsys Global User Survey 2013からの資料である。Photo10は地域別に、現在デザインを行っている対象のプロセスノードを確認したものであるが、一番多いのが45~28nmであるが、次に22/20nm世代が来て、16/14nmもUSA/Indiaでは結構多い。では、次にどんなトランジスタを使う設計か(Photo11)を確認すると、プレナーCMOSが一番多いのは2012年も2013年も同じだが、FinFETを使う設計が増えつつあるのが興味深い。

|

|
|
Photo10:日本は45/40nmが一番多く、次は32/28nm。22nm以下については非常に少ないのがちょっとした特徴 |
Photo11:あと氏は触れなかったが、2013年にはFPGAに切り替えるというユーザーが9%もいるのも面白い。要するにASICをやめてFPGAに切り替えた、という事だと思うが |
Photo12は、どんな理由でFInFETを使うか、という設問であるが、一番重要視されているのがPerformanceで、次にDynamic Powerの削減、電圧削減ときて、ロジック密度向上が最後にくるという感じになっている。

|
|
Photo12:Intelはともかく、TSMCの16nm FinFETでは配線が20nmと同じものなので、ロジック密度はあまり向上しないためだろうか。More densityが半分未満になっているのは興味深い |
Photo13はデザイン中の回路規模である。今度は日本はAsiaの中に含まれているが、100万ゲートを超えるような大規模デザインもそこそこの割合であることがわかる。そのデザインの速度の変遷を示したのがPhoto14であるが、2GHz以上となると携帯向けのハイエンドSoCとIntel/AMDのCPU/SoC程度で、流石にこれは少ない。が、1~2GHz以上となると携帯向けSoCの大半が入り、さらに500MHz以上となるとGPUとかIA機器向けプロセッサなども入ってくる結果、全体の50%にも達するとしている。要するに、どんどんデザインの高速化が進んでいるということだ。

|

|
|
Photo13:ただこれは1Kゲート程度~100万ゲートまである意味均等という感じで、様々な規模のデザインが利用されている事が判る |
Photo14:この割合はあくまでもデザイン数であって出荷数量とは直接リンクしない事に注意 |
最後のものがこれ(Photo15)で、設計の中のClock Domainがいくつあるかを示したもので、中央値は8だが、多いものはもっと極端に多くなる。これも2012年と2013年を比較すると明らかにClock Domainが増加傾向にあるとしている。これは、様々なIPを集めてSoCを構成するようになった結果、それぞれが別のClock Sourceを必要とする場合にはどうしてもDomainが増えてしまうということだそうだ。

|
|
Photo15:一番多いものでは、Clock Domainが400を超えるのだとか |
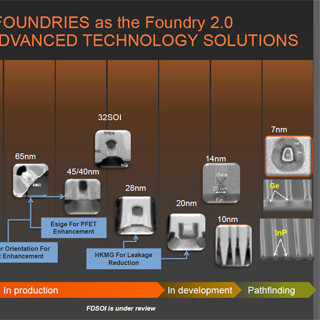
こうしたトレンドに対応して、同社は5nmあたりまでのロードマップを示しており(Photo16)、特に10nm世代では再びムーアの法則に従ったトランジスタコストに収まる、と同社は主張する(Photo17)。氏によれば、14nm以降はトランジスタあたりのコストではなく、機能あたりのコストを考えるべきだとしており、この観点で見れば10nm世代では再びコスト低減が可能になる、としている。ついでに言うと14nmは本来20nmとそれほどコストが変わらないが、同社の14nm世代ではこれを多少なりとも改善できるとしているが、これは後述する。

|

|
|
Photo16:ただ正直言って10nm世代に出てくるIII-V族だの量子井戸だのが、素直に登場する気が全然しないのは気のせいか? |
Photo17:破線がムーアの法則に従ったトランジスタあたりのコスト曲線である。28nm世代あたりまでは概ねムーアの法則にしたがっているが、20~14nm世代ではちょっと高止まりしている |
ちなみにPhoto18は「余談だが皆さんが気になっている事柄なので」(Kengeri氏)と説明されたもので、EUVが何時実現できるか、を見たものである。現在はArF液浸ではもう足りず、Double PatterningとかTriple Patterningを行っているのは御存知の通りで、これがEUVに切り替わると全部Single Patterningになる分、マスクコストも削減できるしThroughputもあがるわけだが、問題は光源の出力が一番良いものでも80W程度しかないことだ。同社の試算によれば、Triple Patterningの場合は120WPH程度、Double Patterningなら170WPH程度で丁度コスト的にマッチするわけで、それを実現できるには最低でも200W~450W程度の光源出力が必要になる。

|
|
Photo18:縦軸がWPH(Wafers Per Hour)で1時間あたりのプロセス処理枚数、横軸が光源の出力である |
実際にはこれだとコストがマッチするだけなので、実際には500~1000W程度の出力が無いと割安にはならないと判断している。実際のところ、同社も10nm世代の立ち上がりにEUVは間に合わないと見ており、なので10nm世代はDouble/Triple PatterningとEUVの両方に対応したものにするという話であった。これにより、例えば量産初期は初期はDouble/Triple Patterningで対応し、あとでEUVに切り替えることでコスト削減を可能にする事も可能だとしている。もっともEUVが何時来ると思うか、とKengeri氏に尋ねたところ、「ここ数年、ずーっと『2年後』と言われてるよね(笑)」という返事が返ってきた。まぁ、これはGLOBALFOUNDRIESというよりも露光装置大手のASMLに聞くべき質問なのであろうが。
さて、他にも若干同社の戦略などが語られた(Foundry 2.0:など)が、これはあまり新しい話ではないので割愛して、3つ目というか本題である14nmプロセスの話を。
米国時間の4月17日に、同社とSamsungが共同で、14nm FinFETに関するライセンス供与のアナウンスがリリースされている。これはどういう意味かというと、14nm FinFETに関してこれまで同社が開発してきた14XMというプロセスの提供を中止し、代わりにSamsungの14LPE/14LPPというプロセスを提供する、という話である(Photo19)。

|
|
Photo19:この結果として、14nmに関してはSamsungとGLOBALFOUNDRIESでFabの互換性がある。実際Fabそのものの同期が取られるという話であった |
当初提供されるのは14LPEで、性能20% Up、もしくは消費電力の35% Downを実現できるとしている(Photo20)。また、これまでGLOBALFOUNDRIESが提供を予定していた14XMでは、配線層が(TSMCと同じく)20nmと共通化されていたので、20nmと14nmでは原理的にダイサイズが縮小されないのに対し、14LPE/14LPPは配線層が異なっており、これによって最大で15%ほどのダイサイズ縮小が可能になったとする(Photo21)。

|

|
|
Photo20:問題はこの20nmはどこのものかであるが、話の筋からすればSamsungの20nmとの比較ではないかと思われる |
Photo21:「最近は大量のメモリを搭載するアプリケーションが増えてきたので、実装密度の向上は非常に重要」(Kengeri氏)だそうだが、だとすれば14XMはどうだったのか? |
ただこの結果として、当然ながら既存の20LPMと今度の14LPE/14LPPの間に互換性はなくなるため、もし仮に「まず20LPMで、次に14XMに移行」というプランを持った顧客が居れば大問題になっただろうが、幸いにというか不幸にもというか、同社の20LPMを積極的に使う大口顧客は殆ど居ない模様で、これは大きな問題にはならなかった様だ。
この結果として、14LPE/14LPPは4カ所のFabで量産体制が整う事になり、大量生産のニーズにも応えられるし、地域的な分散により不測の事態への対応性も高まる、というのが大きなポイントであると氏は説明した(Photo22)。実際、PDKは当然共通になり、ほかの条件もCopy Exactly式に揃えるので、Photo22のどこのFabを使っても同じように生産ができる体制を整えるとしており(Photo23)、これにより迅速な立ち上げが可能になるとしている。

|

|
|
Photo22:ぶっちゃけ、他社を圧倒する資金力でFabをがんがん増設しているTSMCと伍してゆくためには、GLOBALFOUNDRIESとSamsungが同じプロセスにするのは非常に賢明な戦略だし、顧客のメリットにもなるとは思う |
Photo23:PDKが共通というよりも、SamsungのPDKをGLOBALFOUNDRIESも提供するというのが実情に近いかも。実際Samsungの14nmのPDKは2012年末にアナウンスされている |
ちなみに14LPEと14LPPは殆ど同じであるが、14LPPの方が後に提供になり、よりハイパフォーマンスなものになるとしている(Photo24)。すでにPDKはどちらのプロセスに関しても提供開始されており、14LPEのQualificationは完了、第4四半期にRisk Productionを開始し量産は2015年から、というスケジュールが示された。

|
|
Photo24:14LPEと14LPPの違いは別途質問をしたのだが、あまり細かな話は教えてもらえなかった。感じで言えば、同社の28nm LPHと28nm HPP(あるいは28nm SLPと28nm LPH)の違いといった感じなのかもしれない |
さてニュースとしてはこの程度であるが、もうすこし質疑応答などをベースに解説したい。もともとGLOBALFOUNDRIESはIBMの技術をベースにプロセスの開発を行っていたが、IBMが32nm以降はめっきり開発の速度が落ち、昨今ではファウンドリビジネスそのものから売却とかいう話も出ている。その一方でSamsungは20nm/14nmに関してはかなり先行しており、20nm世代は2011年、14nm世代も2012年に基本的な開発は完了している。なので、14XMを捨てて14LPE/14LPPに移行するというシナリオそのものは非常に現実的な選択肢である。実際、2013年位からGLOBALFOUNDRIESがSamsungと同じ半導体製造装置を導入しているという噂は出ており、ある意味発表は時間の問題だったとも言える。
また、すでに14LPEをベースに開発しているという顧客が存在しているそうで、ということは社内的にはかなり早いタイミングで14XMを捨てて14LPE/14LPPに移行する事を決めていたと考えられる。でないと顧客が14XMをベースに本格的に物理設計を始めてしまい、切り替えが大騒ぎになってしまうからだ。Kengeri氏によれば、14XMと14LPEのトランジスタ特性は非常に近く、ツールもあるので移行は簡単だと強調していたが、トランジスタはともかく配置配線に関してはまったく互換性が無いと思われるので、これは簡単では無いだろう。ちなみに14XMのPDKは2012年9月に提供を開始されているが、どの程度のユーザーがこれを使ってすでに設計していたのかは不明である。
あと、FD-SOIについても若干。同社は2012年にSTMicroelectronicsから28nm/20nmのFD-SOIプロセスに関するテクノロジーライセンスを取得しているが、少なくとも現時点でこれを顧客に提供する予定は無いという話だった。これはFinFETに関しても同じで、14/10nm世代でFD-SOIを提供する予定はないとの事。理由としては、まずFD-SOIのウェハコストが高いこと、もう1つは大量生産に耐えるだけのウェハの供給体制がない事を挙げた。ただその一方で、10nm未満のプロセスではFD-SOIが復活するのではないかという見通しを示している。これはこうした微細化プロセスではJunction Isolation等が大問題となるためで、FD-SOIはこれの解決に有利だからという事だそうで、なのでいつかは復活する、とした。ただ当面は顧客がそもそもFD-SOIを望んでいないので、Bulkベースで製造を行うとのことであった。
最後にCost/Functionの話を。例えば14nm世代でSoCを作るとき、AnalogとかRFは必ずしも14nmで製造する必要はないというか、無駄に高くつく。であれば、これを例えばもっと古いプロセスで製造し、様々なPackage Option(2.5/3D Stackingなどを含む)を利用することで、コストを抑えつつ必要なFunctionを提供するという形のソリューションがあることが説明された。要するに、今後は複数のプロセスで製造する方向性になるから、単純にムーアの法則でCost/Transistorを計算しても意味が無い、というのが氏の意図な様だ。