マイクロプロセサにはバグは付き物で珍しくはないが、多分、一番有名なバグは、1994年のPentiumの割り算器のバグであろう。このバグは浮動小数点の割り算器のバグでこのコラムで説明してきた整数の割り算器ではないが、割り算を行うハードウェアとしては、整数の場合は商を1の桁まで求めると終わりであるが、浮動小数点の場合はレジスタのビットの範囲まで割り算ループを繰り返し計算するという違いだけで、割り算器としての基本的な動作は同じである。
Pentiumの割り算器は、最小冗長方式のRadix-4 SRTアルゴリズムを用いているが、Dを16/16から32/16の範囲に正規化し、18/16、21/16、24/16、27/16、30/16で分割する6分割のテーブルを用いている。前に掲げた図12のPDプロットではQi=2の上限の斜めの線が、ちょうど、マスの角に掛かっている点が3箇所あるが、Pentiumの6分割テーブルでは、このような角に掛かる点が5箇所ある。なお、このような不均等な分割をROMで実現しようとすると、16分割と同じになってしまい効率が悪いので、テーブルを真理値表として入力して論理合成で回路を作成したと考えられる。
このようにマスの角に掛かる点があっても、部分剰余Piを正確に計算していれば問題ないのであるが、前の図16のように、高速化のためにCSAを使いサムとキャリーに分けてデータを保持しており、短いビット数のCPAでPiを計算する過程で誤差が入り、本来はQi=2を選択すべきところを上側のDon't Careのマス(一般的に、論理合成する場合、本来は使われないマスの値を任意として、合成される論理回路を最小化する手法が用いられる)を選択してしまうというのが、スタンフォード大学のPratt教授のPentiumの割り算バグを考察した論文の結論である。
バグが顕在化するのは、マスの角ぎりぎりのDとPiになった場合だけなので、発生頻度は低く、Intelは通常のユーザの使用環境では2万7千年に1回の発生頻度である。従って、通常のユーザの使用では支障はないとして、当初、浮動小数点演算を頻繁に使う人だけ交換に応じるという発表をしたが、結局、世論に押されて、申し出があれば、無条件に全数交換することになった。Intelの推定によれば、交換のコストは$475Mとのことで、マイクロプロセサ史上、最も高くついたバグとなった。
Radix-16の割り算器の実現
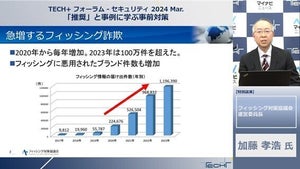
Intelの45nmプロセスを使う最初のプロセサであるPenrynは、1サイクルに4ビットづつ商を求めるRadix-16の割り算器を搭載し、従来のRadix-4の割り算器に較べて、ほぼ2倍の割り算性能になっているというのが、ウリである。次の図のグラフが示すように、 32bビット整数の割り算では、従来のRadix-4の割り算器と較べて60%程度の実行時間となっている。
また、この割り算器は浮動小数点の割り算や平方根演算にも使用され、倍精度浮動小数点の割り算では70%程度の実行時間、平方根では50%弱の実行時間を達成している。
PenrynのRadix-16割り算器の性能(出典:Intel) |
このRadix-16割り算器の作り方であるが、大きく分けて、二通りの方法が考えられる。その一つは、Radix-16のSRT割り算器をまともに作るという方法である。Radix-16の割り算に対して、最小冗長シンボル割り当てを行うと、部分商の一桁は-8~+8の値を取ることになり、Radix-16のSRT割り算器の構成は図17のようになる。
図17:Radix-16 SRT割り算器 |
除数Dの1、2、4、8倍は左シフトで作れるが、3倍、5倍、7倍を作る加算器が必要となる。なお、6倍は3倍の加算器の出力を1ビット左シフトすれば良い。そして、セレクタは9入力と大型化する。また、部分商選択テーブルが、大きく複雑になり、Pentiumの$475Mバグに見られるような、マスの角に掛かるケースが増えるので、設計と検証には注意が必要である。
Radix-16のSRT割り算器は、図-13に示したRadix-4のSRT割り算器と比較すると、アダーが1個から4個、マルチプレクサ入力が3から9に増加し、部分商選択テーブルも4倍程度に増加する。従って、物量としては、3~4倍に増加し、テーブルとマルチプレクサが大型化することによりサイクルタイムが増加し、クロックが低下する恐れがある。
なお、この図では、CSAを使った高速化は適用されていないが、図16と同様に、部分剰余の計算にはCSAを使い、部分商選択テーブルを引くためにCPAを使う構成とすることにより、サイクルタイムを短縮することができるが、同じ手法を適用したRadix-4の割り算器より遅くなることは避けられない。
もう一つの方法は、1サイクルの間にRadix-4の割り算を2回実行するという方法である。デュアルコアのチップを2個、1つのパッケージに入れたからクワッドコアだというのと同じで、ちょっとズルのような感じがするが、1サイクルに4ビットの部分商が得られるので、外側から見ればRadix-16の割り算器である。過去にHPのPA-7100プロセサがRadix-16の割り算を実現していたが、このPA-7100の実装は、倍速のクロックを使って1サイクルに2回、Radix-4の割り算ループを廻すという方式であった。
IntelはかつてのNetBurstアーキテクチャのPentium 4では整数演算器を1サイクルに2回動かすという方式を取っており、高速の演算器を作ることにかけては実績を持っている。従って、筆者は、今回のRadix-16の割り算器も、PA-7100と同様に割り算ループを半サイクルで廻れるように高速の演算回路を作ることにより、1サイクルに2回のRadix-4 SRTを実行したのではないかと推測していたのであるが、果たして、2007年5月のMicroprocessor Forumにおいて、次の図のような構成が発表された。
図18:Intel PenrynのRadix-16割り算器の構成。Radix-4のSRT割り算器が2段接続されている。(2007年5月のMicroprocessor Forumでの発表の図を元に作成) |
ということで、やはり、Radix-4のSRT割り算器を2段接続し、1サイクルに4ビットの部分商を求める構成であった。
この構成では、上側のRadix-4割り算器はクロックサイクルの前半だけ動作し、下側のRadix-4割り算器はクロックサイクルの後半だけ動作している。HPのPA-7100のように倍速クロックを使えば、1個のRadix-4割り算器で済むはずであるが、何故か、割り算器を2個にした構成となっている。もっとも、この2007年5月のMicroprocessor Forumで発表された図は0.5サイクルに2ビットづつの商を求めるということを説明する概念図で、実際の回路は1つしかなく、倍速のクロックで駆動されているという可能性も排除できない。なお、Hybrid Adderと書かれた箱は、CSAとCPAの複合したアダーと説明されている。