ThinCI(Think eyeと発音する)は、Hot Chips 29において、「Graph Streaming Processor(GSP)」と呼ぶディープラーニング用のプロセサを発表した。
|
|
|
ThinCIのGraph Streaming Processorを発表するチーフソフトウェアアーキテクトのVal Cook氏 |
ThinkCIは5年前に創立されたマシンラーニングやコンピュータビジョン向けのシリコンチップを開発する会社である。69人の会社で、95%がエンジニアリングとオペレーションの人員である。
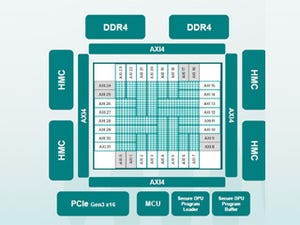
カギとなるIPはGraph Streaming Processorとグラフコンピューティング用のコンパイラである。GSPは、2017年第1四半期からアーリーアクセスプログラムを始めており、2017年第4四半期にはPCIeベースの開発用ボードを出荷する予定であるという。

|
|
ThinCIは5年前に創立され、現在69人の会社である。マシンラーニング、コンピュータビジョン向けのシリコンの開発を行っている (このレポートのすべての図は、ThinCIのVal Cook氏のHot Chips 29での発表スライドのコピーである) |
タスクレベル並列、スレッドレベル並列、データレベル並列を利用し、非常に高い実行効率をもつプロセサを目指しており、グラフの直接的な処理、細粒度のスレッドスケジュール、2次元ブロックの処理、並列のリダクション命令、ハードウェアによる命令スケジューリングなどを特徴とするアーキテクチャになっている。

|
|
ThinCIはグラフを直接処理するアーキテクチャで非常に高い効率をもつプロセサを開発している |
ハードウェアでグラフ処理を行うという点で、Wave ComputingのDPUと似た思想のプロセサである。一方、Wave ComputingのDPUは多数のDPUチップを使う大規模学習システムを狙っているのに対して、ThinCIのGraph Streaming Processor(GSP)は低消費電力で、エッジデバイスでの推論エンジンへの適用を狙っている点が異なる。
タスクグラフは、次の図右のようにタスクレベルの処理のつながりを示すもので、A~Gの各ノードは処理を実行するプログラムである。そして、各ノードは四角い箱で示したバッファにつながっている。バッファはプログラムの出力の構造化されたデータを格納する。したがって、タスクグラフは処理のデータ依存性を明示している。
プログラムはグラフのサブセットであり、ThinCIのハードウェアは、グラフをそのまま実行する。

|
|
右側に示したタスクグラフのノードはプログラムであり、タスクグラフはデータ依存性を明示している。ThinCIのGSPはタスクグラフを処理する |
各ノードを順に処理するSequential Node ProcessingはDSPやGPUが行う実行法で、処理結果をメモリに書き込んで受け渡しを行うので、メモリアクセスが多くなる。DRAMアクセスは、消費電力、アクセスレーテンシの両面でコストが高い処理である。
一方、GSPでの処理ではバッファはストリーム処理の中で、まだ、受け取られていないデータだけを保持すればよく、小さいバッファで済む。バッファのサイズとしてはシーケンシャル処理で必要となるバッファの1%程度で済むという。結果として必要なメモリバンド幅が減り、消費電力も減り性能も上がるという。次の図の右下の絵のように、データは書き込まれるそばから読まれて消費されていくので、バッファが小さくて済むことは分かるが、書き込みのデータ量と読み出しのデータ量は変わらず、アクセスのバンド幅は減らないのではないかと思うのであるが、バンド幅が減ると説明されている。しかし、DRAM上のバッファ経由でデータを受け渡すのに比べてチップ上の小容量のバッファメモリが使えれば、電力が減り、性能が上がるというのは理解できる。
そして、ストリーミングであるので、ソースとなるノードの処理が終わる前に、その出力データを入力とする次の処理が始まるので、タスクレベルの並列性を利用することができる。

|
|
ストリーミング処理は、シーケンシャル処理に比べると小さなバッファでデータが受け渡せ、処理の並列度も高くなる |