英ARMは5月29日、COMPUTEX TAIPEI 2017に合わせて開催した製品発表会において、DynamIQに対応したCortex-A55/A75と、Mali-G71後継となるMali-G72を発表した。

|
Photo01:説明はお馴染みNandan Nayampally氏(VP&GM, Compute Product Group) |
Cortex-A55/A75の概要
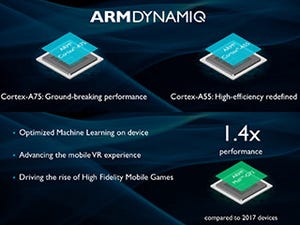
まずCortex-A55/A75であるが、これはどちらもDynamIQに対応した製品となる。DynamIQ自身は3月に発表した、新しいマルチコアのインフラであるが、Interfaceというかbig.LITTLEの制御方法がこれまでと異なっており、従来のコアでは利用することができず、新しいコアでサポートすることになっていた。その新しいコアが今回発表の2製品である。

|
Photo02:Cortex-A75は高性能、Cortex-A55は高性能/消費電力比を狙ったコアとなる |
Cortex-A75は高性能を狙ったコアで、Cortex-A73と比較して最大50%以上の性能改善が実現できたという。このCortex-A75は、Cortex-A72とCortex-A73の両方の後継という位置付けで、
- Mobile Environment(SmartphoneのTDP枠)ではCortex-A73と比較して最大20%のピーク性能改善
- 同じくMobile EnvironmentでのSustained PerformanceはCortex-A73と同等
- Infrastructure Performance(サーバー環境)でCortex-A72より40%の性能アップ
といった数字も示されている。内部的には4命令フェッチ、3命令デコードのSuperScalar/Out-of-Order構成をとっている。
一方のCortex-A55は、Cortex-A53と比較して2.5倍の性能/消費電力比を実現するという(Photo03)。同一プロセス/周波数という条件では、以下のような数字が挙げられている。

|
Photo03:ただしCortex-A75は10nmプロセスを利用した場合で3GHz動作、対してCortex-A73は16nmプロセスで2.4GHz動作となっている |
- CeekbenchでCortex-A53比で21%%の性能改善
- Octane 2.0で同14の性能改善
- LMBench memcpyで同97%の性能改善
- SPECFP 2006で38%の性能改善
- SPECINT 2006で18%の性能改善
一方性能/消費電力比ではSPECINT 2000の場合で次のようなパフォーマンスだという。
- 性能が18%up
- 消費電力は3%up
- 性能/消費電力比は15%改善
つまり、絶対的な消費電力は微妙に増えているが、それよりもIPCの改善が著しいので効率が上がったという話で、性能を同等にするならより動作周波数が下げられるという訳だ。

|
Photo04:ただしCortex-A53は28nm、Cortex-A55は16nmでの製造である |
内部構造は2命令のIn-Order SuparScalarであるが、内部の実行パイプラインは、Load/StoreやNEON/Integerが分離された結果、8本に増えている。こうした性能改善がありながら、絶対的な消費電力を3%upに抑えたあたりが肝ということだろう。
ちなみに両者に共通する特徴として、命令セットにARM v8.2aをサポートしたことが挙げられる。ARM v8.2aの特徴を次にまとめる。
- FP16、あるいはINT 8のdot product演算をサポート。これはCNN(Convolution Neural Network)などML(Machine Learning)の高速化に役立つものである。DynamIQの説明会でも触れられた、AI関連命令の最初のものと思われる。
- Atomic命令のサポート。これはCache Stasingに関連してサポートされるものである。説明は後述。
- Type 2 Hypervisor(KVM)に対応する新しい仮想化関連命令セット(VHE:Virtual Host Extensions)のサポート
などが挙げられる。
ARM v8.2a以外の共通点としては、まずCache Stashingのサポートだ。Cache Stasingを商用プロセッサとして最初にサポートしたのは、旧Freescaleのe500mcだと思うのだが、そのe500mcにおけるCache Stashingの説明はこちらを参照してほしいのだが、要するにキャッシュの一部に専用の領域を設け、ここには直接外部のPeripheralなどからデータを書き込めるようにする技法だ。
これはアクセラレータなどと高速にデータをやり取りする場合に効果的な技法で、e500mcでもNetwork関係のPacket Accelerationとのやり取り向けに搭載されている。Cortex-A55/A75でも同じ目的でこの機構が採用されたようだ。
ちなみにe500mcでは、Stashingエリアの管理のために専用のレジスタが追加されたが、Cortex-A55/A75ではこの管理をAtomic命令を使って行うとのことだった。
続いては、Peripheral Portのサポート。Cache Stasingと直接的な関係はないのだが、「低帯域だが低レイテンシ」な外部I/Oポートが新たに追加された。このポートはCPU毎ではなく、DynamIQで管理されるCPU Group毎に1つ提供される形だ。これは外部アクセラレータとの高速な同期などに利用できると思われる。
このほか、RAS機能の拡充:Data Poisoning、あるいはArchtectual error reportingといった「RAS機能の強化や拡充」、NVDIMMのような不揮発性メモリをDRAMの一部として利用することを念頭においたものと思われる「Clean to persistent memory」のサポートなどが挙げられた。
Cortex-A55/A75でどんなSoCが構成できるか
さて、Cortex-A55/A75でどんなSoCが構成できるかというと、これまでよりも柔軟にコアの数が変更できる(Photo05)と説明があった。

|
Photo05:Cortex-A55で2種類のサイズがあるところが突っ込みどころ |
例えば、
- エントリ向けSoC:Cortex-A55×4
- メインストリームの低いほう向けSoC:Cortex-A55×8
- メインストリームのやや上向けSoC:Cortex-A55×7 + Cortex-A75×1
- ハイエンド向けSoC:Cortex-A55×4 + Cortex-A75×4
というように、全体のコア数とCortex-A55/A75の比率を自在に変えられるので、あとはPPA(Power/Performance/Area)のバランスをどこで取るかを、アプリケーション要件によって合わせればいいという話である。
そしてDynamIQではGPU以外に外部のAcceleratorも同様に接続できるので、さまざまなSoCを作りやすいという話であった(Photo06)。

|
Photo06:右のAcccleratorとの接続は、ACE経由とPeriperal Portの両方が可能なので、データはACE経由、制御はPeripheral Port経由といった形が可能になる |
従来モデルから性能向上を実現した「Mali-G72」
次がMali-G72である(Photo07)。Mali-G72そのものについて、今回は大きな変更がなく、基本的には若干のブラッシュアップである。とはいえ効率が17~25%ほど改善している(Photo08)。

|
Photo07:説明は、これもお馴染みJem Davies氏(VP, GM & Fellow, Media Processing Group) |

|
Photo08:絶対性能で言えば、Mali-G71比で40% upという数字も示された |
一応流行ということでML関連については、FP32に加えてFP16を利用する場合もあるということで、その場合の性能/消費電力比は最大で17%ほど改善されているとされる(Photo09)。

|
| MPhoto09:ここでConvolutionではなくGEMMの結果を示すあたりが、あまりAIに力を入れる気がない事を物語っている |
ただCPU側と違って、INT 8をサポートする予定は一切なく、あくまでもMali-G71の延長で効率を改善することで、「AI関連でも性能がやや改善するよ」という程度のアピールでしかない。むしろ主戦場はゲームとかVRであって、こちらでの性能改善が主となる(Photo10)。

|
| MPhoto10:絶対性能に関しては、スケーラビリティを拡張(最大32コアまでサポート)したことで、最大構成だとMali-G71の3倍ちかくまであげられる事になる |
ところで効率改善をどう成し遂げたか、という理由の一端がこちらである(Photo11)。これはGamevilのAfterpulseを実施した際の、メモリへの書き込み量を比較したものである。

|
| MPhoto11:もちろんメモリ帯域の効率化以外にも効率化のポイントはあると思われる |
Mali-G72ではMRT(Multi Render Target)用のバッファの量を2倍に増やしたことで、書き込み頻度を42%削減、加えて、新たに追加されたPLS(Pixel Local Storage)を活用することで、さらに45%削減することに成功した。これにより、トータルで68%もの削減を実現した。CPUで言うならL2の増量とL3の追加により、性能が改善したというあたりだろうか。これにより効率化と性能が改善した。
説明会の内容としてはこの程度だが、実はもう少し細かい話を聞いているので、こちらは別記事として改めてお届けしたいと思う。