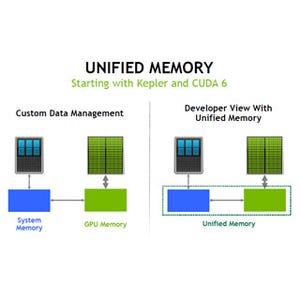
例を挙げると、次の図の2行目のcudaMallocManagedでユニファイドメモリ領域を確保し、3行目ではcudaMemsetで0を書き込んでいる。この動作はGPUで行われている。そして、次のforループはCPUで実行されるので、CPUのアクセスに応じて、必要なページがCPUメモリに移動されて計算が行われる。
最後のReduce_sumはGPUで実行されるカーネルであるので、GPUのアクセスに伴ってページがCPUからGPUに移動されるという動きになる。

|
|
arrayというユニファイドメモリを確保し、GPU、CPU、GPUとアクセスに伴ってデータが移動する例 |
このプログラムをK40 GPUで実行させた場合のプロファイラ出力が次の図である。まず、Mallocが両方で行われ、次のMemsetはGPUで実行され、CPUでアップデートが行われる。CPUがアクセスするデータが、CPUメモリに存在しないので、GPUメモリから領域全体がコピーされてきている。
そして、後のReduce_sumはGPUで実行されるので、領域全体のGPU側へコピーが発生している。

|
|
前記の例をK40 GPUで実行した場合のプロファイラ出力 |
ヒストグラムの作成や動的なキューの作成のような処理は、どの区分に幾つのデータが入るかはやって見なければ分からない。このため、溢れないように余裕をもってメモリを確保しておく必要がある。

|
|
どの区分にどれだけのデータが入るか分からないので、余裕をもってメモリを用意しておく必要がある |
しかし、Pascalでは、デマンドページがサポートされたことで、必要になった時点でメモリを使うので、GPU側のメモリは必要になった時点で確保すれば良いため、メモリを浪費しないで済む。

|
|
メモリはアクセスが必要ななった時点でオンデマンドで確保されるので、使われないメモリを用意しておく必要は無い |
また、グラフを辿る問題では、膨大なサイズのグラフの内のどのノードが使われるのかはデータ依存で、実行してみないと分からない。大きなグラフの場合は、グラフ全体をGPUメモリに入れられないが、デマンドページであれば、使われるノードのデータだけをGPUメモリに持って来ればよい。

|
|
グラフ問題では、どのノードがアクセスされるかは、データ依存であり事前には分からない。全ノードのデータをGPUメモリに入れられない場合でも、デマンドページなら、必要なノードのデータだけをコピーしてくれば済む |
グラフの各エッジには、それぞれ、最大流量が決まっており、始点から終点のノードまでの最大流量を求める最大フロー問題も、このような問題である。

|
|
各エッジの流量が決まっているグラフで、始点から終点までの最大フローを求める問題は、どのノードがアクセスされるか分からないこと |
最大フロー問題を扱うには、KeplerやMaxwell GPUでは、アクセスされる可能性のあるすべてのグラフデータをGPUメモリに置いておく必要がある。GPUメモリに入らない部分は、CPUメモリをマップして使用したり、アプリで入れ替えを行なったりする必要がある。しかし、Pascalの場合は、アクセスする部分のデータだけがオンデマンドで移動されるので、グラフ全体のデータをGPU側で持つ必要がない。このため、GPUメモリに収まらない大きなグラフでも簡単に処理できる。

|
|
Kepler、Maxwellでは、グラフの全データをGPU側メモリに置く必要があったが、Pascalでは、オンデマンドで必要なデータだけを持ってくるので、GPUメモリに入らない大きなグラフの処理も簡単に行うことができる |
アレイの中にポインタが含まれているディープコピーのケースでは、アレイだけをGPUメモリにコピーしても、ポインタの先のデータをコピーしなければ、データをアクセスできない。このためには、GPUメモリにコピーを入れるメモリを確保し、コピーを行って、ポインタを付け替えるという処理が必要であり、かなり手間が掛かる。
しかし、デマンドページングのユニファイドメモリになると、ポインタを含むアレイをコピーした状態で、ポインタで指されたデータをアクセスしようとすると、そのデータはGPUメモリには存在しないので、デマンドページングでそのデータをGPUメモリに持ってきてアクセスできるようにしてくれる。従って、ディープコピーのケースでも意識せずに処理ができる。成瀬氏のスライドには、ディープコピーのケースは含まれていないが、これもPascalのユニファイドメモリで可能になった重要なケースである。