GTC Japan 2016において、NVIDIAの成瀬氏がPascalの「ユニファイドメモリ」について発表を行った。筆者は、Pascalで行われた一番重要な機能拡張は、このデマンドページングによるユニファイドメモリではないかと思っている。
CUDAやOpenCLでプログラムを書かれた経験をお持ちの方は、CPU側とGPU側でメモリを確保し、その間でのデータ転送を明示的に書くのにうんざりされているのではないかと思う。それも少数のMallocで確保した領域なら我慢できる。しかし、ホスト側の配列がデータで、その要素が構造体で、構造体の中に子配列へのポインタがあるというケースでは、元の配列のコピーだけは済まず、それぞれのポインタが指す子配列の領域をGPU側に確保して、データをコピーし、元の構造体のポインタの指す先を新たに確保したGPUメモリのアドレスに付け替えるという処理が必要になる。そして、子配列の中に、さらに構造体があり、その中にポインタがあるようなケースでは、もう、やっていられないと思っても不思議ではない。
AoS(Array of Structures:構造体の並列)ではなく、SoA(Structure of Arrays:配列の構造体)型のデータとすれば、このような問題はないが、巨大なプログラムで、AoSからSoAへの書き換えを行う気には、まず、なれないし、プログラムの可読性も悪くなってしまう。
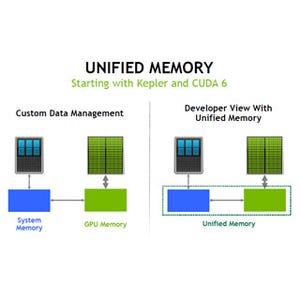
ここで登場した強い味方が、Pascalのユニファイドメモリである。ユニファイドメモリは、Kepler、Maxwellでもサポートされていたが、GPUのカーネルを起動するときには、カーネルが使う可能性のあるデータはすべてGPUメモリ上に置いておく必要があった。
このため、cudaMallocManagedで確保したユニファイドメモリ領域のptrという変数を最初にアクセスするのがCPUであると、ptrのデータはCPUメモリに移動され、カーネルを起動するときに、カーネルが使う、すべてのデータはGPUメモリに移動されるという動きになる。

|
|
Kepler、Maxwellでは、CPUとGPUは同じメモリをアクセスできるが、カーネル起動前に、すべてのデータをGPUメモリに置いておく必要がある (このレポートのすべての図は、GTC Japan 2016におけるNVIDIAの成瀬氏の発表スライドを撮影したものである) |
しかし、Pascalでは、オンデマンドでページを移動することができるようになった。つまり、あるアドレスをGPUがアクセスしようとすると、CPUが使っている場合でも、そのアドレスを含むページ(4KB)の使用権をGPUに渡し、データをCPUメモリからGPUメモリにコピーする。CPUがあるアドレスをアクセスする場合も同様に、CPUに使用権が渡され、GPUからデータが移動される。
CPUとGPUが同じページのメモリの使用権を争うと、PCI Express経由でのページのコピーが頻発してしまうが、このやり方で、CPU、GPUともにアクセスしたいデータが自由に使えるユニファイドメモリが実現できる。
そして、このやり方であると、そのときにアクセスするメモリだけがあればよいので、GPUに搭載されたメモリより大きなメモリ領域を使うこと(Oversubscription)もできる。

|
|
Pascalではページ単位のオンデマンドのページ移動が可能になり、制約のないユニファイドメモリとなった。GPUには、その時に必要なメモリがあればよいので、GPUの物理メモリより大きなデータも扱える |