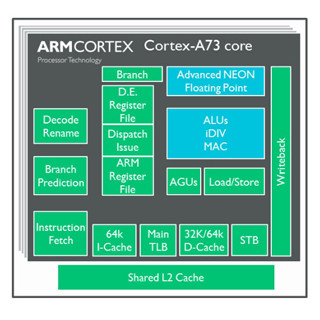
COMPUTEX TAIPEI初日にあたる5月30日、ARMは台北でプレスカンファレンスを開催し、ここで2017年のフラグシップモバイル機でVRを実現させるためのコンポーネント、という位置付けで「Cortex-A73」と「Mali-G71」を発表した。前回、Cortex-A73について説明を行ったが、今回はMali-G71について少し詳しく説明したいと思う。
Mali-G71は、第3世代の「Bifrostアーキテクチャ」を搭載する最初の製品、という位置付けである(Photo01)。元々台北におけるARMの発表は、Cortex-A73とMali-G71を組み合わせることでVR/ARに対応できるシステムが構築できる、というストーリーが基本になっており、当然ながらその際の主役はCortex-A73ではなくMali-G71である(Photo02)。このMali-G71が目標とするのは、4Kスクリーン/120HzでのVR再生能力であり(Photo03)、スムーズなAR再生能力である(Photo04)。

|

|
|
Photo01:名称に関するルール。どうでもいいが、Utgardに関しては"Single letter and two numbering system"がそもそも通用していない気がするのは筆者だけか? |
Photo02:Mali-T880 MP12を搭載するSamsung Galaxy S7+Gear VRでもそれなりにVR体験が楽しめるが、今後はさらにそのニーズが強まると考えられる |

|

|
|
Photo03:パイプラインのレイテンシが4ms、という設計目標はかなり意欲的である。もちろんディスクリートGPUならば可能だが、スマートフォンの熱設計電力の中でこれを実現しなければいけない |
Photo04:ARの場合は「何をさせるか」次第でCPUの負荷が大きく変わるが、GPUの負荷が高い事そのものは変わらない |
こうした高い性能を低い消費電力で実現するための1つの工夫が、「フルキャッシュコヒーレンシ(Full-Cache Coherency)」である(Photo05)。これにより、データの移動の必要が削減され、データ移動に要する消費電力を大幅に削減できたとする。

|
|
Photo05:Mali-G71はCPUとGPUのキャッシュの間に完全なキャッシュコヒーレンシが保たれる |
また、従来のOpenGL/ESは引き続きサポートするが、それと共にVulkan APIをフルサポートすることで、より高い描画性能を少ないオーバーヘッドで実現できるとする(Photo06)。

|
|
Photo06:VulkanそのものはMali-T800ですでにサポート済みであるが、Bifrostでは当初からこれのサポートを念頭においていたとする |
では実際にどんな性能か? という1つの答えがこちら(Photo07)。同じ条件であればMali-T880と比較してより性能が高く、かつ最大で32コア(Mali-T880は最大16コア)までの構成が可能となっている。また4コア~32コアまで構成をスケーラブルに変更でき(Photo08)、幅広い用途に利用できるとする。ピーク性能、という意味では16コア構成のMali-G71のGPU性能は、2015年のノートPCと同程度のGPU性能がある(Photo09)、というのが同社の主張だ。

|

|

|
|
Photo07:直接の性能でないところがいかにもだが、電力効率はおおむね性能/消費電力比と判断できる |
Photo08:技術的には1コアも可能らしいが、意味があるのか? という問題はある |
Photo09:これが何を指すのかは難しいところだが、恐らくはIntel HD Graphics 500シリーズあたりがターゲットで、同じIntelでもIris/Iris Proでは無い様な気がする |
ではそのBiforestコアはどんなものか? という話である。まず大きな違いはSIMDエンジンの採用をやめたことである(Photo10)。基本的にはCortex-A73同様、省電力や省サイズを念頭に置きつつ、この制約のなかでどう性能を改善するか、という点に特徴が置かれており、純粋な性能で言えば1.5倍に改善されたとする(Photo11)。全体の構成がこちら(Photo12)で、シェーダコア(Shader Core)の数が増減する形になる。

|

|

|
|
Photo10:BifrostはScalar ISAをサポートする。Mali-G71はそのBifrostの最初の製品という位置付けであり、今後さらに後継製品が出ることを予定していると思われる |
Photo11:Clauseベースの命令というのは見慣れない表現であるが、これは後述。Quad-baseがキーである |
Photo12:L2キャッシュセグメントの数も増減できる様になっている。コアの最大数が32というのは、Mali-G71世代におけるコントロールファブリックが最大32コアまでサポートしているから、という話 |
そのコアの内部を比較したのがPhoto13とPhoto14である。ではその「Quad」とは何か? という話がここからである。

|

|
|
Photo13:こちらがMidgardの構成。ベースとなるのがスレッドで、スレッドごとにピクセルの処理をALUパイプを利用して行う形となる |
Photo14:Bifrostでは、スレッドに代わってQuadという新しい管理単位が発生している |
ほとんどのSIMDの場合、偶数単位での実装になる。前世代アーキテクチャである「Midgard」の場合、128bit幅のSIMDなので16bitなら×8、32bitなら×4、64bitなら×2での処理となるが、これはGPGPU的に使う場合には便利な一方、GPUとして画面のPixel処理を行う場合、どうしても無駄が出る(Photo15)。また、うまくスレッドを制御して順次実行できる様にしないと、SIMDエンジンの効率が落ちる事になる。

|
|
Photo15:可能性としては、×6とか×12の構成も考えられなくもないが、ベクターの幅が広がるほど効率が落ちやすくなるので、現実問題としてあまり得策とは言いがたい |
そこでBiforestでは、4つのスレッドの処理を一旦まとめた上で、これを転置して処理させるというやり方で効率を改善した(Photo16)。これによりSIMD(という用語が適切でないのでARMはQuadという用語を利用したのだと思われる)の効率化(Photo15のように遊ぶレーンが出てこない)を図った形だ。またこのアーキテクチャであれば、命令キャッシュのフェッチが、従来のSIMDのように、毎サイクルに全ベクター分の命令をフェッチする必要がないというのもARMの主張で、これによって命令キャッシュの帯域が節約でき、より大規模なプログラムの実行が可能になるし、消費電力の削減にも繋がるとしている。もちろんこの方式だと、理論上はQuadの分断が起こりえる可能性はある(Photo17)訳だが、実際にはこんなに小さい単位で分割されるケースが少ないし、そもそもQuadが小さいから余程頻発するのでなければ影響は少ない、としている。

|

|
|
Photo16:実際にはサイクル4では次のQuadの処理に取り掛かる事が出来る |
Photo17:実際にはifで分岐される両側の処理量がここまで少ないというケースはレアであろう。もちろん可能性としては分断が発生する余地は常にあるが、問題は頻度ということだ |
話を戻すと、Photo14でComputer FrontendはMidgardと変わらない。ただMidgardはピクセル単位でスレッドを生成するのに対し、Bifrostではここで4ピクセル分をまとめてQuadを生成し(これがQuad Creatorの作業)、ついでそのQuadをまとめて(これがQuad Manager)、その後に各々のExecution Engineに割り当てるという形をとる。1サイクルあたり3つのQuadを実行可能(=結果として4ピクセル分の処理が可能)であり、2つのALUによって2ピクセル分(正確に書けば2.666ピクセル分)の処理が1サイクルで可能なMidgardに比べると50%の性能改善、実際にはMidgardは無駄があるから、これを勘案するとMidgardの2倍の性能で処理ができる、という訳だ。またMidgardでは一体化されていた「Load/Store」と「Attribute」、「Varying」の各ユニットがBifrostでは分離して並行に実施できるようになっており、これによっても若干の性能改善は期待できそうだ。