米国は、次世代のフラグシップスパコンである「Summit」の導入に向けた準備を加速しており、その状況についてGTC 2015で発表が行われた。Oak Ridge National Laboratoryが導入するSummitは、現在Top500 2位のTitanの後継となるマシンである。このマシンはIBMが主契約者となり、NVIDIAとMellanoxが協力するという体制で開発される。
その性能は、実アプリで、Titanの5倍以上の性能が要求されており、IBMのPOWER9 CPUとNVIDIAのVolt GPUからなる計算ノード約3400ノードからなるスパコンとなる。
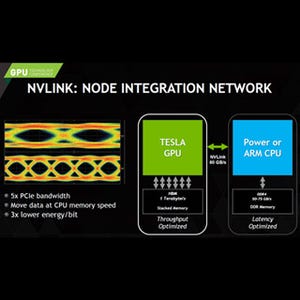
VoltaはHBM(High Bandwidth Memory)を使い、GDDR5を超えるメモリバンド幅を実現する。そして各ノードにはHBMとCPU側のDDR4メモリの合計で512GBを超えるメモリを搭載する。NVLINKの採用で、両方のメモリはCPUからもGPUからもアクセスできるコヒーレントな共通メモリになる。
さらに、各ノードは800GBのNVRAMを搭載する。このNVRAMは、ストレージアクセスのバンド幅を改善するBurst Buffer、あるいは拡張メモリとして使われる。ファイルシステムとしてはIBMのGPFSが使われ、ストレージ全体としては1TB/sのIOバンド幅で120PBの容量を持つ。
ノード間のインタコネクトは100Gb/sのEDR InfiniBand ×4を使い、ノンブロッキングのFat Treeを構成する。この部分はMellanoxが担当すると考えられる。

|
|
SummitスパコンはIBMが主契約者でNVIDIAとMellanoxが協力。ノードはIBM POWER9 CPUとNVIDIAのVolta GPUをNVLINKで接続する |
各ノードは40TFlopsを超える演算性能を持つと書かれており、3400ノードでは136PFlopsを超えるピーク演算性能となる。Volta GPUの演算性能については情報が無いが、仮に5TFlopsとすると1ノードに8個程度搭載されるのではないかと思われる。
Summitは現有のTitanと比較すると5~10倍のアプリ性能をもつ。ノードのピーク演算性能は、Titanの1.4TFから40TF以上と大型のノードとなる。このため、ノード数は約3400とTitanの1/5以下に減る。TitanのインタコネクトはCrayのGemini LSIを使う3Dトーラスであるが、SummitではEDR InfiniBandのFat Treeに変わる。
消費電力は10MWであり、Titanの9MWからは微増である。

|
|
現在のTitanと次世代のSummitの諸元の比較。アプリ性能は5~10倍だが、大型のノードを使うので、ノート数は1/5以下となる。消費電力は10MWでTitanからは微増である |
ORNLはCenter for Application Readiness (CAAR)という組織を作って、アプリケーションの準備を進めている。
Titanの前のシステムであるJaguarからTitanへの性能向上は、原子レベルで物性をシミュレートするWL-LSMSでは3.8倍の性能向上、燃焼シミュレーションのS3Dは2.2倍、分子シミュレーションのLAMMPSは7.4倍、中性子の移送シミュレーションのDenovoは3.8倍であったが、TitanからSummitでは5倍~10倍の性能向上がターゲットであり、これを実現するアプリケーションの開発がCAARのミッションである。
Summitでは並列に実行されるスレッド数がTitanに比べてずっと多くなるので、並列実行可能なスレッドを増やすようにプログラムを書き換える必要がある。また、HBMを使うなどのハードウェア的なメモリバンド幅の改善もあるが、ソフトウェア側でも、データアクセスの局所性を増して、メモリバンド幅をより有効に利用できるようにプログラムを書きなおすなどの努力が必要となる。

|
|
Oak Ridge National Laboratoryで使われる主要なプログラムの性能を改善するのがCenter for Application Readiness (CAAR)のミッション |
また、ArgonneやNERSCのシステムは同一のアーキテクチャではないので、CAARの開発するソフトウェアは、それらのシステムでも高い性能が得られる作りになっていなければならない。
このため、Summmitだけに最適化するのではなく、MPI+X(OpenMP、OpenACC)、PGAS+X、DSL(Domain Specific Language)などのプログラミングパラダイムを使い、他のシステムにも移植が容易となるような適当な抽象化を行っておくことが必要になる。

|
|
CAARの仕事はSummitで性能のでるアプリを開発するだけでなく、それらのアプリが他のスパコンでも高い性能を持つポータビリティの確保も重要である |
将来の大規模スパコンとしては、同じアーキテクチャのコアを数百万個使うメニーコア方式と、CPUとGPUのハイブリッド方式が考えられる。NERSCのColiスパコンはIntelのKnights Landingを使うノードを9300個持つメニーコアシステムで、ノード間接続にはCrayのAriesインタコネクトを使う。Summitは前述の通り、ハイブリッド方式のスパコンである。

|
|
NERSCのColiスパコンはIntelのKnights Landingを使うメニーコア方式、SummitはCPU+GPUのハイブリッド、Argonneのマシンは未定。これらすべてのスパコンで高い性能を発揮するアプリソフトが要求される |
ポータビリティを確保する作戦としては、データアクセスの局所性とスレッド並列性を増すことが第1である。これはメニーコアにもハイブリッドにも効果がある。そして、第2は、ポータブルなライブラリを使うことである。マシンアーキテクチャの違いを吸収するライブラリを開発し、異なるアーキテクチャのスパコンでも同じソースコードのアプリで高い性能が得られるようにする。
MPI+OpenMP 4.0が共通のプログラミングモデルとして確立する可能性もある。しかし、これを実現するには、多くの仕事が残っているという。そして、NVIDIAのCUDAなどの特定のアーキテクチャ向けの言語は使わず、ポータブルな開発を推奨する。

|
|
データアクセスの局所性を高めることとより多くのスレッド並列性を見つけることが最重要。そしてハードの違いをライブラリで吸収する。さらにポータビリティの高い開発を推奨する |
Oak Ridge、NERSC、Argonneの開発スケジュールは次のようになっている。時期的にはNERSCのColiが一番早く、2016年のF4Q(米国政府の会計年度は前年の10月1日から始まるので、2016年のF4Qは2016年の7月~9月)から運転が始まる。Summitは2018年のF3Qからの運用を予定しており、Argonneも同時期となっている。
アプリケーションを準備するCAARの活動は今年のF3Qから第1期の開発が始まり、2016年のFQ4から第2期の開発が始まるという計画となっている。

|
|
Oak Ridge、NERSC、Argonneの開発スケジュール |