現在、米国を代表するスパコンはTop500 2位のOak Ridge国立研究所の「Titan」や3位のLawrence Livermore国立研究所の「Sequoia」である。Sequoiaは2012年6月、Titanは2012年11月にTop500の1位を取っており、2017年には設置後5年となり更新時期を迎える。ということで、これらのスパコンを置き換えるPre Exaの次期のフラグシップスパコンを開発する「CORAL(Collaboration of Oak Ridge、Argonne、and Livermore)プロジェクト」が進められている。
そして、2014年11月14日に、Oak RidgeとLivermoreの2システムはIBMのOpenPOWERプラットフォームにNVIDIAのGPUを搭載するというシステムを選択したことが発表された。これらのシステムは、2017年には設置が完了し、稼働を開始する予定である。

|
|
プレスブリーフフィングを行う、NVIDIA Japanの林部長 |
こうした発表に併せる形でNVIDIA Japanが、このほど、CORALスパコンに関するプレスブリーフィングを開催した。説明者は、NVIDIA Japanのプラットフォームビジネス本部の林憲一部長である。
Oak Ridge、Argonne、Livermoreの3つの研究所は、それぞれ新たなスパコンを導入するが、今回、NVIDIAとIBMに決まったのは、Oak ridgeの「Summit」というシステムとLivermoreの「Sierra」というシステムである。TitanをリプレースするSummitが一番規模が大きいとみられ、ピーク演算性能は150~300PFlopsと発表されており、科学アプリケーションの実行でTitanの10倍の性能を目標としている。そして、LivermoreのSequoiaをリプレースするSierraは100PFlops以上で、Sequoiaの5倍以上の科学アプリケーション実行性能と発表されている。

|
|
CORALプロジェクトの2台のスパコンをIBMとNVIDIAのチームが開発する |
なお、Argonneの「Mira」をリプレースするシステムがどのようになるかは、まだ、発表されていない。
SummitとSierraは、IBMの次世代のPOWER9 CPUとNVIDIAの次々世代のVolta GPUを組み合わせ、ピーク演算性能40TFlops以上の計算ノードを作るという。Summitシステムでは、この計算ノードを3400ノード以上使用することになる。なお、40TFlops×3400=136PFlopsにしかならないので、300PFlopsにするにはノード数を2倍以上にする必要がある。最終的にどの程度の性能になるかは、獲得できる予算によるという。
NVIDIAのVolta GPUは第2世代のNVLinkを装備する。NVLinkは次世代のPascal GPUから採用されるGPU間を接続する高速リンクで、4リンクを並列に使うと80GB/sのバンド幅を持つ。これはPCIe3.0のx16リンクの5倍のバンド幅である。そして、Voltaの世代になると、POWER9 CPUもNVLinkをサポートし、CPUとGPUをNVLinkで接続できるようになる。また、第2世代のNVLinkは、200GB/sとバンド幅が2.5倍に向上し、コヒーレンシ制御をサポートする。これにより、CPU側が持つ512GB以上のDDR4メモリとGPU側のHBMメモリが共通のメモリとして見え、CPU側からもGPU側からもアクセスできるようになるという。
現在は、CPUがノード間通信のMPIを実行し、GPU側のメモリを獲得し、受け取ったデータをGPUメモリにコピーして、GPUの処理カーネルを起動して処理を行い、処理が終了するとその逆の手順を踏んでMPIでデータを送信する。このCPUとGPU間のデータのコピーと実行権の受け渡しが必要なことがGPUを使う計算処理を複雑にしているが、NVLinkで論理的な共通メモリが実現し、アクセス時間やバンド幅的にも差が小さくなれば、プログラミングのハードルがかなり下がると期待される。
Summitの計算ノードは、メインメモリの拡張やバーストバッファとして使える800GBのNVRAMを搭載する。計算ノード間は、MellanoxのEDR InfiniBandで接続され、ファイルシステムはIBMのGPFSで、容量は120PB、I/Oバンド幅は1TB/sとなる。
そして、消費電力は10MWで、これはTitanの10%増しに抑えられている。

|
|
Summitシステムの主な仕様 |
Titanは、Top500に登録されたLINPACK性能が17.59PFlopsで消費電力が8.029MWであるので、エネルギー効率は2.19MFlops/Wである。Titanと同じピーク比率と考えると、ピーク300PFlopsのSummitのLINPACK性能は約200PFlopsで、これで10MWの電力とすると20MFlops/Wとなる。これはTitanの9倍のエネルギー効率である。
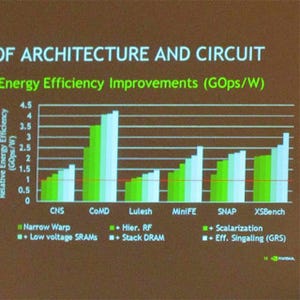
Summitシステムの提案構成と、ほぼ同じコストのCPUオンリーのシステムの性能を比較したものが次の図である。この比較に含まれているアプリケーションは、エネルギー省指定の優先順位の高いTR-1ベンチマークに含まれているものである。左側のグラフはフルシステムのスケーラビリティを見るテストで、CPU+GPUシステムは、CPUオンリーのシステムと比較して2.5~13倍高い性能が得られている。一方、右側のグラフは多種のジョブを混ぜて実行した場合のスループットを見るテストで、こちらでも3~12倍のスループットが得られている。

|
|
左はフルシステムの性能のスケーラビリティを評価するテストで、同じコストで比較すると、CPUオンリーのシステムと比べて、CPU+GPUシステムは2.5~13倍高い性能が得られる。右は各種のアプリケーションを混合して実行する場合のスループットを評価するテストで、3~12倍のスループットが得られる |
多くのアプリケーションでは、GPUでの実行に向く高並列で実行できる部分と、CPUでの高速実行が必要な並列度の低い部分があり、両方を組み合わせたヘテロジニアスな計算システムの方が、同じコストで比較すると、性能の高いシステムにできるという。アクセラレータを使うか使わないかは、最早、議論の対象ではなく、アクセラレータは必須となっており、CPUのアーキテクチャ、GPUのアーキテクチャ、ノード内のインタコネクト、ノード間のインタコネクトをどうするかが問題という。この点で、Pre ExaシステムであるSummitとSierraで選択された
- ヘテロジニアスなコンピューティングモデル
- 高速なNVLinkインタコネクト
- NVIDIAのGPUプラットフォーム
- IBMのOpenPOWERプラットフォーム
はExascaleへと続く最良の道であると、Oak RidgeとLivermore国立研究所は判断したという。