筑波大の朴教授のHA-PACSとCOMAスパコンとアプリケーション
続いて、筑波大学の朴泰祐 教授が発表を行った。筑波大はNVIDIA GPUを使う「HA-PACS」というスパコンとXeon Phiを使う「COMA」というスパコンを持っている。HA-PACSのLINPACK性能は421TFlops、COMAは746TFlopsという。
MIC(Knights Corner)はx86のコードがそのまま動くというのが売りであるが、それでは高い性能は期待できない。512bit幅の演算ができるAVXを意識したり、ハードを直接制御するIntrinsicなどを明示的に使ったプログラミングをすると劇的に性能が上がる場合が多いという。また、実効メモリバンド幅を改善するPrefetchの指定もほぼ必須という。
プログラミングのやり方として、GPUの場合はCUDA+MPIが標準で、通信はCPUが行い、それとGPU上で動作するKernelとの連携が必要で、プログラミングが非常に煩雑になるという。
MICの場合はCPUでMPIを処理し、MICには計算量の多い処理をオフロードする使い方と、MIC側でMPIを処理するnative+MPIという使い方があるが、後者は極めて低速だという。しかし、プログラムをオフロード型に書き直すのは面倒である。この点に関しては、次世代のKnights Landingで大幅に改善されることが期待されるという。

|

|
|
MICは使えているかというと、x86のプログラムそのままでも動くが高い性能は期待できない。MIC向けのチューニングが必須という |
GPUの場合は、CPUでMPIを実行し、GPUのKernelと連携するプログラムは煩雑。MICはMIC側でMPIを実行するnativeならプログラムは楽だが、極めて性能が低い。この問題はKnights Landingで改善が期待されるという |
今後のメニーコア(MIC)に関しては、東大と共同調達を行う「JCAHPC(Joint Center for Advanced HPC)」で、2015年度にピーク性能30PFlopsと国内最大のスパコンを設置する。このスパコンにはメニーコアプロセサ(Knight Landing)を搭載することを想定している。COMAは、このスパコンに先駆けてメニーコア向けのアプリケーションを開発するベースとしての役割があるという。
まとめとして、筑波大はスペース性能、電力性能の観点からアクセラレータを使う計算処理が重要と考えて研究を行っている。COMAを使ってメニーコアのアプリケーションの開発を推進しているが、Intrinsicを積極的に利用しないと性能がでないのが問題で、Knights Landingでの性能向上とコンパイラの性能向上に期待する。東大の柏キャンパスに設置されるJCAHPCと並行して、筑波大の独自リソースとしてはアクセラレータを積極的に用いたシステムを中心に開発・導入を続けて行く方針であるという。

|

|
|
2015年度に東大との共同調達で、メニーコアプロセサを使い30PFlopsの性能を持つJCAHPCスパコンを設置する。 |
筑波大のセンターはスペース性能、電力性能の観点からアクセラレータを使うシステムを推進。JCAHPCと並行して、筑波大でも開発を行っていく |
京大の深沢准教授のMHDコードの性能評価
最後に発表を行ったのは、京都大学(京大)の深沢圭一郎 准教授である。発表のタイトルは「Xeon PhiとGPUを利用したMHDシミュレーションコードの性能評価」である。Magneto Hydro Dynamicsは電磁流体の解析コードで、深沢准教授は太陽風と地球の磁気圏の相互作用をシミュレーションしている。

|

|
|
太陽風が強まると、衛星や、場合によっては地上の電力網などに被害がでる |
太陽風と地球の磁界の相互作用をMHDで計算した結果の例 |
フラットなMPIでMICを使った場合は25~30GFlopsと性能が出なかったが、Hybrid MPI化することにより50GFlops近くまで性能が向上した。しかし、次の左側の図のように、プロセス数とスレッド数でかなり性能が変わる。
Xeon Phi向けのチューニングとしてよく言われる、配列のアライメント、ベクトル化のチェック、環境変数の設定などを行った結果、右側の図に示すように、配列のアライメントは48.97GFlopsから79.27GFlopsと大幅に性能が向上したが、強制インライン展開によるベクトル化は性能がダウン、また環境変数の設定も多少性能ダウン。コンパイルオプションの指定は79.27GFlopsから83.93GFlopsと若干の性能改善という結果になった。

|

|
|
OpenMPと組み合わせるHybrid並列化で40~50GFlopsに性能が向上した |
配列のアライメントなどよく言われる最適化を試した結果。配列のアライメントは大きな効果。インライン展開によるベクトル化は逆効果 |
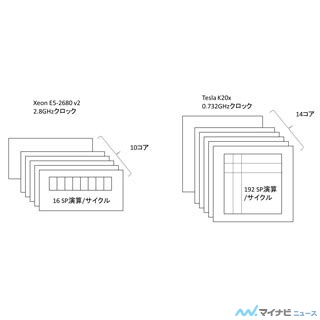
次の左側の図のように、K20m GPU 1チップでの性能は、NVIDIAの成瀬氏の協力を得てチューニングを行った結果、153.34GFlopsとなり、MICの83.93GFlopsの2倍弱の性能が得られた。また、8チップのWeak Scaling場合も0.91倍のスケーラビリティとなり、CPUほどではないが、まあ、良い値と言える。この結果はディレクティブレベルのチューニングなので、CUDAで書き直せば、もっと性能があがるかも知れないという。
まとめとして、Xeon Phiでは、OpenMP+MPIのハイブリッドMPI化でFlat MPIの約1.4倍の性能が得られた。そして64バイト単位に配列をアラインすることとコンパイラオプションの設定が効果的で、83.93GFlopsまで性能が上がった。ピーク演算性能に対する比率では、Xeon PhiはCPUの1/3程度であるが、チップあたりの性能では、SPARC64 IXfx(9fx)より高い性能であった。
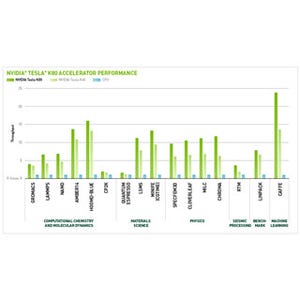
GPUは1チップでXeon Phiの2倍近い性能で、8チップでは1TFlopsを超える性能が得られた。
そして、一般にヘテロな構成での最適化は難しいので、単体アクセラレータで動作することを希望すると述べた。

|

|
|
K20m GPUでチューニングを行うと153.4GFlopsとMICの2倍近い性能。8チップでは1TFlopsを超える。スケーラビリティはCPUほどではないが、まあ、良いと言える |
MHDコードでMICとGPUの性能比較を行った。Flat MPIに比べてHybrid MPIでは1.4倍の性能。その他のチューニングを組み合わせて83.9TFlops性能となった。ヘテロのチューニングは難しいので、単体アクセラレータで動くものが欲しい |