富士通は、Hot Chips 26において、京コンピュータの10倍の性能の100PFlops級のスパコンを構築するための新CPU「SPARC64 XIfxプロセサ」を発表した。

|
|
Hot Chips 26で、SPARC64 XIfxを発表する富士通の次世代テクニカルコンピューティング開発本部の吉田利雄氏 |
このプロセサ名は、SPARC64 CPUのXI(11代)目のプロセサで、fxが付いているのは科学技術計算向けのプロセサであることを意味している。また、次の図に見られるように、10PFlopsの京から、1ExaFlopsマシンへの中間ステップとなるプロセサでもある。

|
|
富士通のSPARC64プロセサの開発の歴史 (この記事のすべての図は、Hot Chips 26における吉田氏の発表スライドより抜粋) |
そして、SPARC64 XIfxの目玉としては、合計34コアという多数のコアの集積、HPC-ACE2と呼ぶ第2世代のHPC向け命令の追加、HMC(Hybrid Memory Cube)の採用によるメモリバンド幅の改善、さらに、ノード間を接続するTofuインタコネクトの第2世代への進化が挙げられている。
次の図は、SPARC64 XIfxのチップ写真と主要な諸元を示している。まず、目を惹くのが左右に16個ずつ、合計32個のプロセサコアである。さらに中央に2個のアシスタントコアがあり、全体では34コアのチップとなっている。そしてチップの中央部分を24MBのL2キャッシュが占めている。

|
|
SPARC64 XIfxのチップ写真と諸元 |
そして、左右の辺はHMCのインタフェースが占め、上辺にはTofu2インタコネクトのコントローラとインタフェースが配置され、下辺にはPCI Expressのコントローラとインタフェースが配置されえいる。
製造プロセスはTSMCの20nmプロセスで、総トランジスタ数は3.75Bトランジスタである。クロックは2.2GHzで動作し、ピーク演算性能は1.1TFlops(倍精度浮動小数点演算)で、メモリバンド幅はin/outそれぞれ240GB/s、Tofu2インタコネクトのバンド幅は125GB/s×2となっている。
チップサイズは発表されなかったが、前世代のSPARC64 Xが28nmプロセスで、16コア+24MBキャッシュ、2.95BTrで587.5mm2であったが、SPARC64 XIfxは20nmプロセスであるので、これよりは小さくなっているのではないかと思われる。
前世代のHPC向けプロセサであるSPARC64 IXfx(以下、9fxと略記)はピーク演算性能は236.5GFlopsであったので、SPARC64 XIfxでは、演算性能が4.65倍に向上している。また、メモリバンド幅は85GB/sから合計では480GB/sと5.65倍に向上し、Tofuインタコネクトのバンド幅は50GB/s×2であったのが、Tofu2では125GB/s×2と2.5倍になっている。
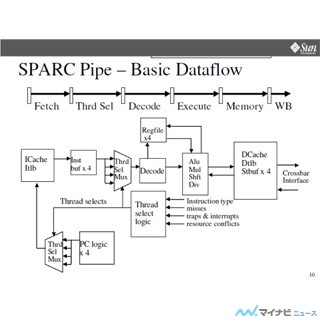
CPUコアのマイクロアーキテクチャは次の図に示すように、前世代の9fxとかなり似ているが、幾つかの点で改良されている。

|
|
SPARC64 XIfxプロセサコアのパイプライン構成 |
大きな違いは、SIMDの演算とロードストア系が256bit幅に倍増された点である。また、従来は、SIMD演算器は倍精度浮動小数点演算にフォーカスされた設計で、単精度の場合でも同じ性能であったが、SPARC64 XIfxでは、(IntelプロセサやGPUと同様に)単精度の場合は2倍の演算ができるようになった。
結果として、次の図に示すように、基本的な演算カーネルの性能は、前世代のプロセサと比べて倍精度の場合は3.23倍、単精度の場合は6.18倍に向上している。なお、この性能向上は、クロックの向上の寄与分も含んだ値である。

|
|
SIMDの256bit化で基本的なカーネルの性能は、倍精度で3.23倍、単精度では6.18倍に向上 |
そして、従来のSIMDロードストアは連続アドレスのメモリしかアクセスできなかったが、今回は、一定のアドレス間隔で飛び飛びにアクセスするストライドアクセスとアドレスベクタを指定して、どのアドレスでもアクセスできる間接アクセスを行う命令が追加されている。

|
|
一定のアドレス間隔で飛び飛びにアクセスするストライドロードストア命令 |
ストライドの間隔は2~7要素に制限されている、その範囲に入っていれば、3.6倍あまりの高速化が得られる。

|
|
レジスタに格納したアドレスに従って、任意のアドレスをアクセスする間接ロードストア命令 |