GPUなどのアクセラレータを比較的容易に利用できるようにするOpenACC
OpenACCは、NVIDIAやAMDのGPU、あるいはIntelのXeon Phiなどのアクセラレータを比較的容易に利用できるようにするプログラミング仕様である。このOpenACCの標準化を行っている団体のPresidentであるDuncan Poole氏から、OpenACCの現状について聞いた。

|
|
NVIDIAのStrategic AlliancesマネージャでOpen ACC のPresidentを兼任するDuncan Poole氏 |
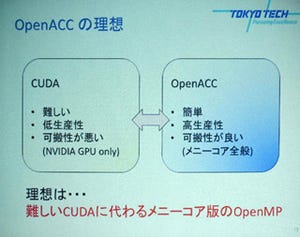
GPUのプログラミング言語としてNVIDIAのCUDAや、業界団体が推進しているOpenCLなどがあるが、そのプログラミングは比較的難しく、GPUを取っ付き難いものにしていると言われる。
マルチコアのCPUを有効に利用するOpenMPというプログラミング仕様がある。次の例のように、#pragma omp parallel forというディレクティブ(指示行)を書くと、次のfor文の実行を指定したコア数のプロセサで並列に実行するプログラムを作ってくれる。
#pragma omp parallel for
for(i = 0; i < 10000; i++)
{
// (処理するプログラム)
}
pthreadsでコア数分のスレッドを作り、それぞれのスレッドに10000回のforループのどの部分を分担させるかを指示して実行させ、すべての並列スレッドの終了を待ち合わせて次に進むという手順を一々記述するのに比べると、非常に簡単にプログラムを並列化できる。このため、OpenMPは、スーパーコンピュータ(スパコン)の世界では15年以上の歴史があり、標準的に使用されている。
このOpenMPの標準化グループの中でのGPUのようなアクセラレータ向けのOpenMPの検討のペースがGPUの進歩に追随できていないことから、NVIDIA、CRAY、PGI、CAPSなどのメンバーが独立して作りあげたのがOpenACCである。OpenMPが15年以上の歴史があるのに比べて、OpenACCは第1版の仕様が公開されたのが2012年11月で、まだ、1年の歴史しかない新しい標準化である。しかし、CAPSとPGIという2つのコンパイラメーカーとスパコンの老舗のCRAYがコンパイラを製品化している。なお、PGIは2013年7月に買収され、現在はNVIDIAの1部門になっている。

|
|
OpenACCのロードマップ。2012年11月の第1版公開から、3社がコンパイラを製品化。2013年6月に第2版公開。という状況 |
また、2013年6月には第2版の仕様を公開し、CRAYはすでに、第2版準拠のコンパイラを出し、コンパイラメーカ2社も、近く、製品を出す予定という状況になっている。
CAPSは、CPUとしてARMもサポートし、アクセラレータとしてAMDのGPUやIntelのXeon Phiもサポートしている。また、PGIもNVIDIAのGPU以外にもサポートを広げようとしているという。
基本的な考え方はOpenMPと同じ
OpenACCの、基本的な考え方はOpenMPと同じで、#pragma acc parallel loopという指示行を追加すると、次のforループをGPUで実行するカーネルプログラムに変換してくれる。OpenMPとOpenACCで大きく違うのは、OpenMPは、元々は共通メモリを想定しておりデータのコピーの必要は無いが、OpenACCが想定するCPU+GPUの環境では、CPUメモリとGPUメモリは独立で、GPUでカーネルプログラムを動かすためには、CPUメモリのデータをGPUメモリにコピーする必要がある。また、カーネルプログラムの処理が終わったら、GPUメモリからCPUメモリにデータをコピーする必要があるという点である。

|
|
CPUにはレイテンシに最適化したメモリ、GPUにはストリーム処理の最適化したメモリが必要で、独立したメモリが必要になる。このため、OpenACCでは両者の間のデータのコピーが必要になる |
#pragma acc parallel loopという指示行を書けば、この開始時のCPUメモリからGPUメモリへのコピーと終了時のGPUメモリからCPUメモリへのコピーもOpenACCコンパイラが面倒を見てくれる。
しかし、処理結果をCPUメモリにコピーして終わりでGPUメモリを解放とは限らず、結果をGPUメモリに残して次の処理に使えば、次のカーネルプログラムの開始時にはGPUメモリへのコピーが不要になるというような場合があり、開始時、終了時のメモリの扱いを指定する各種のオプションがある。常にコピーを行うやりかたでもGPUを使うことはできるが、コピーに時間がかかり、CPU単独でやる場合に比べて性能が上がらないということも起こる。したがって、OpenACCを使っても、性能を上げるためには、ムダを省くためには色々な指示行とそのオプションを指定してチューニングを行うことが必要になる。