SC12において、NVIDIAのGPU Accelerated Computingビジネス部門のCTOであるSteve Scott氏が「The Evolution of GPU Accelerated Computing」と題して招待講演を行った。

|
|
SC12で招待講演を行うNVIDIAのSteve Scott氏 |
GPUは、以前は固定機能の描画用のパイプラインで構成されていたが、描画処理の高度化に伴ってプログラムが可能な構成に進化し、GeForce FXからはプログラマブルなシェーダーが取り入れられた。

|
|
NVIDIAのGPUは、1998年のRiva 128からプログラム可能な方向に進化してきた。(以下のスライドは、SC12におけるScott氏の講演資料を撮影したもの) |
当初は、GPUハードウェアの機能不足やグラフィックス用のOpenGL言語でのプログラムが必要など、科学技術計算への適用は難しかったが、ハードウェアの進化とCUDAの提供などで、環境が整備されてきた。
そして、Teslaで倍精度浮動小数点演算を取り入れ、Fermiでは倍精度浮動小数点演算性能を大幅に引き上げ、大規模なスパコンでは必須のECCも取り入れた。これにより2010年頃からTop500の中でGPUを搭載するシステム数が急増している。

|
|
初代Teslaで倍精度浮動小数点演算を取り入れ、FermiでECCの採用、浮動小数点演算性能の大幅向上を行い、Top500でGPUを使うシステム数が急増 |
2012年に発表したKepler GPUでは、192CUDAコアを持つSMXを採用してエネルギー効率を改善するとともに、Hyper-QとDynamic Parallelism機能を追加し、プログラム実行の柔軟性を増し、性能も向上させている。

|

|
|
GPUを分割して複数のカーネルを同時並列に実行するHyper-Q。CUDAコアの利用率を上げて2.5倍に性能が向上(CP2Kの例) |
業務フロー作成画面GPUで実行するカーネルから、直接他のカーネルの呼び出しを行うDynamic Parallelismにより、コードサイズが半減し、性能も2倍に向上(Quicksortの例) |
Xeon E5-2687 CPUに、もう1個CPUを付けた場合を1として、K20X、あるいはM2090 GPUを付けた場合の性能を比較したものが次のスライドである。5種のプログラムでK20Xを付加した場合は、デュアルCPUと比較して2.7倍~10.2倍の性能が得られている。

|
|
Xeon E5-2687 CPUに第2のCPUを付けた場合とK20X、M2090を付けた場合の性能向上を示す |
最新のスーパーコンピュータ(スパコン)であるNCSAの「BlueWaters」では、3000台以上のTesla(モデル名は公表されていないが、Kepler GPUを使うK20Xと思われる)GPU、Top500 1位の「Titan」では18,688台のK20X GPUを使用している。

|

|
|
NCSAのBlueWaters(左)は3000台以上のGPUを使用。Top500 1位のTitan(右)は18,688台のK20X GPUを使用 |
|
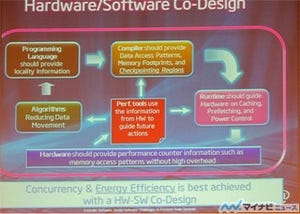
プロセサのクロックの向上は止まり、コンピュータは速くはなっていない、幅が広がっただけであり、HPCのアプリケーションは多数のスレッドで並列に処理するスループットアプリにならなければならない。また、消費電力の観点からデータアクセスの局所性が重要であり、局所性を明示的に管理できるプログラミングモデルが必要である。さらに、それがハードウェア依存でなく移植性が高いものでなければならないという。
そして、その1つの解としてOpenACCを示した。

|
|
移植性の高い並列処理記述としてOpenACCを推進している |
そして、GPUの将来の方向性として、NVIDIAがDARPAのUHPCプロジェクトで2018年をターゲットに開発を進めているEchelonを示した。EchelonチップはLOC0~7の8個の汎用高性能プロセサコアと256個のGPU風のStreaming Multiprocessor、1024個の256KB L2キャッシュとDRAM、インタコネクトのインタフェースなどを集積する。このチップ1個で16TFlopsの演算性能を持ち512+GBのDRAMメモリを接続する。
キャビネットにこのモジュールを256個収容すると、演算性能は4PFlops、メモリ量は128TBとなる。このキャビネットを並べ、システムインタコネクトで接続してExaFlopsのEchlonシステムを作るというプランである。

|
|
2018年の実現を目指すEchelonコンピュートノードとスパコンシステム |
GPUによるアクセラレーションは短い期間に大きな発展を遂げ、プログラムも容易になり、より汎用処理ができるようになった。今後の進化は、より高度な集積、汎用性の向上、エネルギーやオーバヘッドを低減するという方向にファーカスする。これが将来のコンピュータの作り方であると結んだ。

|
|
今後は、高度の集積、汎用性の向上、エネルギーとオーバヘッドの低減にフォーカスして開発を続ける |