■前回: 【レポート】IDF Fall 2010 - 大原雄介の「Sandy Bridge」徹底解説・その2
キャッシュとRing Bus
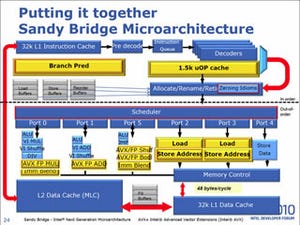
続いてはキャッシュである。Sandy Bridgeの場合、L1/L2キャッシュに関しては従来のNehalem同様に、
L1:命令/データ分離 32KB/8-way×2
L2:命令/データ共用 256KB/4-way
であると見られる。Core 2→Nehalemに関してはL2の構造が変更になった事もあって色々変わったが、現在公開されている情報を元にする限り、Nehalem→Sandy Bridgeに関してはL1/L2に関しては構造・アクセス速度・帯域などは特に変化が無いようだ。ただし呼び方はちょっと変わり、L2がMLC(Middle Level Cache)、L3はLLC(Last Level Cache)となった。その割にL1がFLC(First Level Cache)とならないあたりがいまいち首尾一貫していない感じは受けるが、これはL3の構造が変わり、CPU以外もアクセスすることと無関係ではないのかもしれない。
大きく変わったのはLLC(つまりL3キャッシュ)である。従来はUnifiedの4MBなり8MBのL3として、コアとは独立した形で扱われていたが、今回からコアに「弱い結合関係を持つ」キャッシュとして扱われることになった(Photo01)。どうもこのコアの数とLLCの数は比例するようだ。理論的には、例えば2コアだけどLLCが4ブロックとか、逆に4コアでLLCが2ブロックといった構成も可能な筈だが、そうした構成が無いのは恐らくSandy Bridgeのモジュラ構造が「CPUコアとLLC 1ブロックを一つのモジュラとする」という形に決めているためだろう。これは、Ring BusがLLCと一体化するかたちで構成されていることと無縁ではないと思われる。

|
Photo01: これは4コアのケースで、LLCも4ブロックである。後述する2コアではLLCも2ブロックになっている。恐らくサーバー向けのSandy Bridge-EN(6コアないし8コア)ではLLCも6ないし8ブロックになると見られる。ここにあるように、コアの電圧/動作周波数で動作する、というあたりがコアと分離できない最大の理由だろう。 |
さて、そんな訳で物理的な構造は各コアとLLCが一体化されているが、論理上はコアとLLCは分離されている。各LLCとSystem Agent、それに(Desktop向けの場合は)Graphicsは独自のRing Busで相互に接続されており、各コアやSystem Agent/Graphicsは、このRing BusのI/Fを経由してLLCと接続するという形になっている(Photo02)。

|
Photo02: Ring BusはLLC側に実装されている。このあたりも、LLCとコアが一体化されている理由といってよいかもしれない。 |
このRing Busの構造がかなり興味深い。塩田氏の記事にもある通り、このRing BusはData/Request/Acknowledge/Snoopの4つがある。という事は、恐らく各Ringは独立に動作するということでもある。Data以外の帯域は明確にされていないが、恐らく8bit程度(特にSnoop ringは更に帯域が必要だから、ひょっとすると16bit程度)の幅を持つ「準」二重Ringと見做してよい。
何が「準」なのか、という説明を絡めてちょっと動き方を。図1~3は説明の簡略化のため、2コア+GPUの構成を考えてみた。図1はCore 1がLLC Block 1にあるデータをアクセスする場合だ。このケースではCore 1はまずRingのI/Fにリクエストを出し(①)、RingのI/Fは自身のBlockにあると判断し、そのリクエストを自身に送る(②)。その結果、LLC Block 1はRing I/Fにデータを返し(③)、Ring I/FからCore 1に送られる(④)という具合だ。

|
図1 |
では他のBlockのLLCにあったらどうなるか? というのが図2である。Core 1はRingのI/Fにリクエストを出すが(①)、Ring I/Fは要求されるデータはLLC Block2にあると判断し、それをRingの下り方向に乗せる(②)。次のCycleで到達したリクエストは、LLC Block2に送り出され(③)、その返答が次のサイクルにRing I/Fに戻ってくる(④)。その返答はRingの上り方向に乗り(⑤)、次のCycleにCore 1に返される(⑥)という訳だ。

|
図2 |
逆に、メモリアクセスが発生した場合が図3だ。Core 1はRingのI/Fにリクエストを出すが(①)、Ring I/Fは要求されるデータがキャッシュに無いと判断し、Ringの上り方向に乗せる(②)。次のCycleでSystem Agentに到達したリクエストはメモリコントローラに送り出され(③)、そこから外部のDDR3メモリをアクセスに行き(④)、その結果が再びメモリコントローラ経由でSystem Agentに戻ってくる(⑤)。Memory Agentはその結果を再びRing Busに送り出し(⑥)、次のCycleにCore 1に返される(⑦)という訳だ。

|
図3 |
準二重と書いたのは、つまりCore 1/Core 2に関して言えば、上り下りのどちらにも(必要があれば同時に両方に)送り出せる仕組みになっているからで、従ってCoreに関しては二重と言って良い。問題はSystem AgentとGPUである。Intelのプレゼンテーションを見る限り、内蔵するGPUは2 RingStopを持っているのだが、実装はRingの下端となっている関係で、事実上1 RingStopと変わらない。またSystem AgentはRing Stopが一つとIntelの資料にも記載されており、従ってSystem AgentとGPUに関しては一方向のRing Busと見做すことも出来る。
このRing Busのアーキテクチャを最初に採用したのは、Nehalem-EXである(Photo03)。Nehalem-EXは8つのコアを完全に二重化されたRing Busで繋ぎ、Sandy Bridgeで言うところのSystem AganetにあたるCA(Cache Agent)もやはり2 Ringstopを持つ構造である。ただNehalem-EXの様な大規模システムはともかく、Sandy Bridgeの様にDesktopやMobileを念頭に置いたシステムでは、流石に完全二重化のバス構成とはしにくかったようだ。とりあえず煩雑にアクセスが起きると思われるCPUコアだけは、ほぼ同等のアクセス性能が持てる構造にしたのだと思われる。

|
Photo03: これは2009年にIntelがHotChipsで発表したNehalem-EXの内部構造のスライドから。 |